R语言数据挖掘实战案例:电商评论情感分析

随着网上购物的流行,各大电商竞争激烈,为了提高客户服务质量,除了打价格战外,了解客户的需求点,倾听客户的心声也越来越重要,其中重要的方式 就是对消费者的文本评论进行数据挖掘.今天通过学习《R语言数据挖掘实战》之案例:电商评论与数据分析,从目标到操作内容分享给大家。
本文的结构如下

1.要达到的目标
通过对客户的评论,进行一系列的方法进行分析,得出客户对于某个商品的各方面的态度和情感倾向,以及客户注重商品的哪些属性,商品的优点和缺点分别是什么,商品的卖点是什么,等等..
2.文本挖掘主要的思想.
由于语言数据的特殊性,我们主要是将一篇句子中的关键词提取出来,从而将一个评论的关键词也提取出来,然后根据关键词所占的权重,这里我们用空间向量的模型,将每个特征关键词转化为数字向量,然后计算其距离,然后聚类,得到情感的三类,分别是正面的,负面的,中性的.用以代表客户对商品的情感倾向.
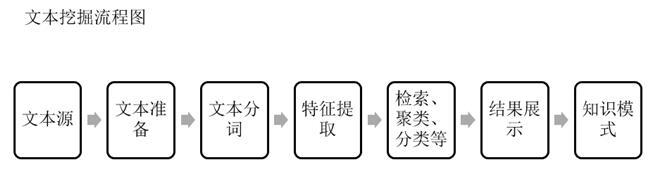
3.文本挖掘的主要流程:
4.案例流程简介与原理介绍及软件操作
4.1数据的爬取
首先下载八爪鱼软件,链接是http://www.bazhuayu.com/download,下载安装后,注册账号登录, 界面如上:
点击快速开始—新建任务,输入任务名点击下一步,打开京东美的热水器页面
复制制页面的地址到八爪鱼中去如下图: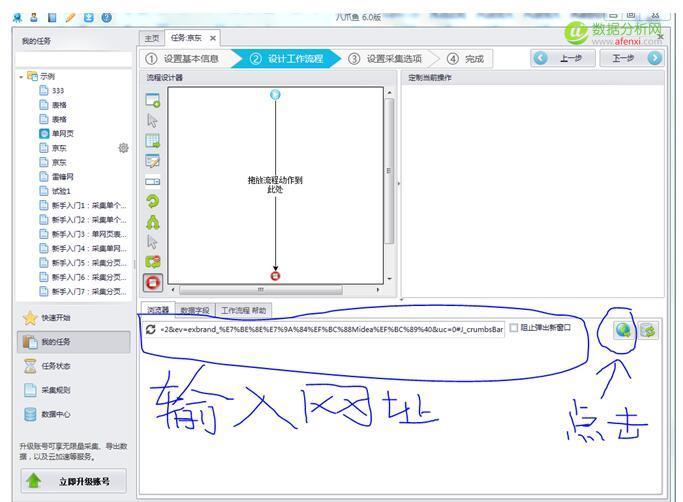
观察网页的类型,由于包含美的热水器的页面不止一页,下面有翻页按钮,因此我们需要建立一个循环点击下一页, 然后在八爪鱼中的京东页面上点击下一页,在弹出的对话列表中点击循环点击下一页,如图: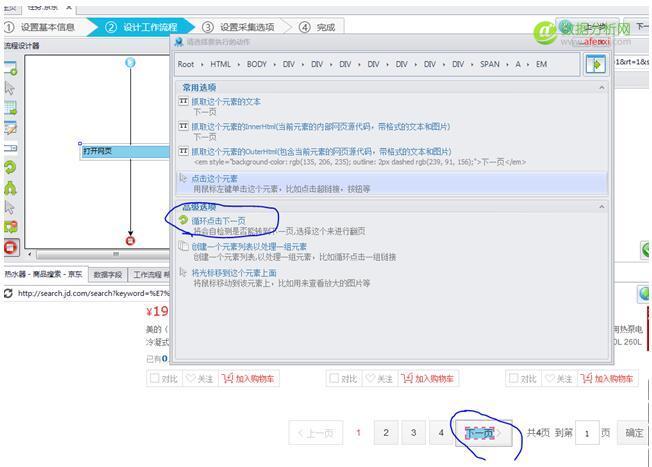
然后点击一个商品,在弹出的页面中点击添加一个元素列表以处理一祖元素–再点击添加到列表—继续编辑列表,接下来我们点击另一商品的名字,在弹出的页面上点击添加到列表,这样软件便自动识别了页面中的其他商品,再点击创建列表完成,再点击循环,这样就创建了一个循环抓取页面中商品的列表,
然后软件自动跳转到第一个商品的具体页面,我们点击评论,在弹出页面中点击 点击这个元素,看到评论也有很多页,这时我们又需要创建一个循环列表,同上,点击下一页—循环点击.然后点击我们需要抓取的评论文本,在弹出页面中点击创建一个元素列表以处理一组元素—-点击添加到列表—继续编辑列表,然后点击第2个评论在弹出页面中点击添加到列表—循环,再点击评论的文本选择抓取这个元素的文本.好了,此时软件会循环抓取本页面的文本,如图:

都点击完成成后,我们再看设计器发现有4个循环,第一个是翻页,第二个是循环点击每一个商品,第三个是评论页翻页,第4个是循环抓取评论文本,这样我们需要把第4个循环内嵌在第3个循环里面去,然后再整体内嵌到第2个循环里面去,再整体内嵌到第1个循环里面去,这样的意思就是,先点下一页,再点商品,再点下一特,再抓取评论,这套动作循环.那么我们在设计器中只需拖动第4个循环到第3个循环再这样拖动下去.即可: 拖动结果如下:,再点下一步—下一步–单击采集就OK 了.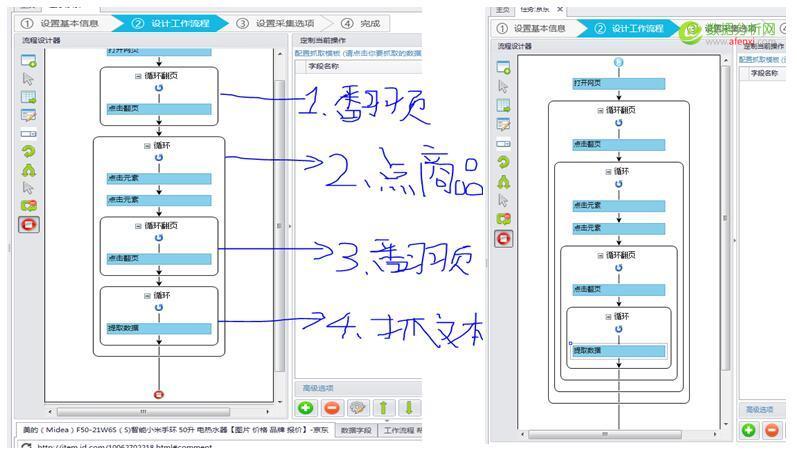 4.2文本去重
4.2文本去重
本例使用了京东平台下对于美的热水器的客户评论作为分析对象,按照流程,首先我们使用八爪鱼在京东网站上爬取了客户对于美的热水器的评论,部分数据如下!

进行简单的观察,我们可以发现评论的一些特点,
文本短,基本上大量的评论就是一句话.
情感倾向明显:明显的词汇 如”好” “可以”
语言不规范:会出现一些网络用词,符号,数字等
重复性大:一句话出现词语重复
数据量大.
故我们需要对这些数据进行数据预处理,先进行数据清洗,
编辑距离去重其实就是一种字符串之间相似度计算的方法。给定两个字符串,将字符串A转化为字符串B所需要的删除、插入、替换等操作步骤的数量就叫做从A到B的编辑路径。而最短的编辑路径就叫字符串A、B的编辑距离。比如,“还没正式使用,不知道怎样,但安装的材料费确实有点高,380”与“还没使用,不知道质量如何,但安装的材料费确实贵,380”的编辑距离就是9.
首先,针对重复的评论我们要去重,即删掉重复的评论.
另外一句话中出现的重复词汇,这会影响一个评论中关键词在整体中出现的频率太高而影响分析结果.我们要将其压缩.
还有一些无意义的评论,像是自动好评的,我们要识别并删去.
4.3压缩语句的规则:
1.若读入与上列表相同,下为空,则放下
2.若读入与上列表相同,下有,判断重复, 清空下表
3.若读入与上列表相同,下有,判断不重,清空上下
4.若读入与上列表不同,字符>=2,判断重复,清空上下
5.若读入与上列表不同,下为空,判断不重,继续放上
6.若读入与上列表不同,下有,判断不重,放下
7.读完后,判断上下,若重则压缩.
4.4然后我们再进行中文的分词,分词的大致原理是:
中文分词是指将一段汉字序列切分成独立的词。分词结果的准确性对文本挖掘效果至关重要。目前分词算法主要包括四种:字符串匹配算法、基于理解的算法、基于统计的方法和基于机器学习的算法。
1.字符串匹配算法是将待分的文本串和词典中的词进行精确匹配,如果词典中的字符串出现在当前的待分的文本中,说明匹配成功。常用的匹配算法主要有正向最大匹配、逆向最大匹配、双向最大匹配和最小切分。
2.基于理解的算法是通过模拟现实中人对某个句子的理解的效果进行分词。这种方法需要进行句法结构分析,同时需要使用大量的语言知识和信息,比较复杂。
3.基于统计的方法是利用统计的思想进行分词。单词由单字构成,在文本中,相邻字共同出现的次数越多,他们构成词的概率就越大;因此可以利用字之间的共现概率来反映词的几率,统计相邻字的共现次数,计算它们的共现概率。当共现概率高于设定的阈值时,可以认为它们可能构成了词
4.最后是基于机器学习的方法:利用机器学习进行模型构建。构建大量已分词的文本作为训练数据,利用机器学习算法进行模型训练,利用模型对未知文本进行分词。
4.5得到分词结果后,
我们知道,在句子中经常会有一些”了””啊””但是”这些句子的语气词,关联词,介词等等,这些词语对于句子的特征没有贡献,我们可以将其去除,另外还有一些专有名词,针对此次分析案例,评论中经常会出现”热水器”,”中国”这是我们已知的,因为我们本来就是对于热水器的评论进行分析,故这些属于无用信息.我们也可以删除.那么这里就要去除这些词.一般是通过建立的自定义词库来删除.
4.6 我们处理完分词结果后,
便可以进行统计,画出词频云图,来大致的了解那些关键词的情况,借此对于我们下一步的分析,提供思考的材料.操作如下:

4.7 有了分词结果后,
我们便开始着手建模分析了,在模型的选择面前,有很多方法,但总结下来就只有两类,分别向量空间模型和概率模型,这里分别介绍一个代表模型
模型一: TF-IDF法:

方法B:将出现的所有词包含的属性作为维度,再将词与每个属性的关系作为坐标,然后来定位一篇文档在向量空间里的位置.
但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
模型二:.LDA模型
传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF-IDF等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似的。
举个例子,有两个句子分别如下:
“乔布斯离我们而去了。”
“苹果价格会不会降?”
可以看到上面这两个句子没有共同出现的单词,但这两个句子是相似的,如果按传统的方法判断这两个句子肯定不相似,所以在判断文档相关性的时候需要考虑到文档的语义,而语义挖掘的利器是主题模型,LDA就是其中一种比较有效的模型。
LDA模型是一个无监督的生成主题模型,其假设:文档集中的文档是按照一定的概率共享隐含主题集合,隐含主题集合则由相关词构成。这里一共有三个集合,分别是文档集、主题集和词集。文档集到主题集服从概率分布,词集到主题集也服从概率分布。现在我们已知文档集和词集,根据贝叶斯定理我们就有可能求出主题集。具体的算法非常复杂,这里不做多的解释,有兴趣的同学可以参看如下资料
http://www.52analysis.com/shujuwajue/2609.html
http://blog.csdn.net/huagong_a … 37616
4.8 项目总结
1.数据的复杂性更高,文本挖掘面对的非结构性语言,且文本很复杂.
2.流程不同,文本挖掘更注重预处理阶段
3.总的流程如下:

5.应用领域:
1.舆情分析
2.搜索引擎优化
3.其他各行各业的辅助应用
6.分析工具:
ROST CM 6是武汉大学沈阳教授研发编码的国内目前唯一的以辅助人文社会科学研究的大型免费社会计算平台。该软件可以实现微博分析、聊天分析、全网分析、网站分析、浏览分析、分词、词频统计、英文词频统计、流量分析、聚类分析等一系列文本分析,用户量超过7000,遍布海内外100多所大学,包括剑桥大学、日本北海道大学、北京大学、清华大学、香港城市大学、澳门大学众多高校。下载地址: http://www.121down.com/soft/softview-38078.html
RStudio是一种R语言的集成开发环境(IDE),其亮点是出色的界面设计及编程辅助工具。它可以在多种平台上运行,包括windows,Mac,Ubuntu,以及网页版。另外这个软件是免费和开源的,可以在官方网页:www.rstudio.org
上下载。
7.1 Rostcm6实现:
打开软件ROSTCM6
这是处理前的文本内容,我们将爬取到的数据,只去除评论这一字段,然后保存为TXT格式,打开如下,按照流程我们先去除重复和字符,英文,数字等项.
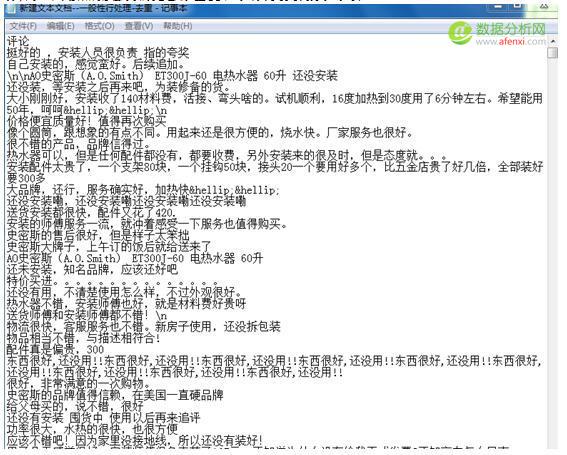
2.点 文本处理–一般性处理—处理条件选 “凡是重复的行只保留一行”与”把所有行中包含的英文字符全部删掉” 用来去掉英文和数字等字符
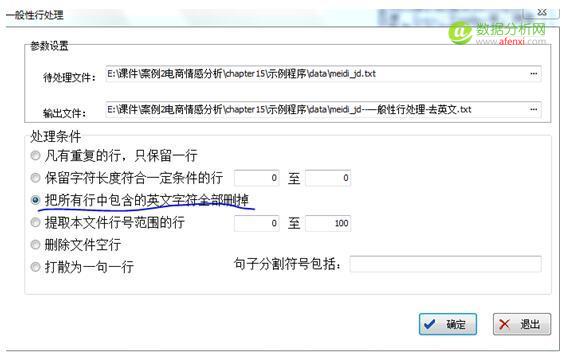
这是处理后的文档内容,可以看到数字和英文都被删除了. 3.接下来, 再进行分词处理. 点 功能分析 —-分词 (这里可以选择自定义词库,比如搜狗词库,或者其他)
3.接下来, 再进行分词处理. 点 功能分析 —-分词 (这里可以选择自定义词库,比如搜狗词库,或者其他)
得分词处理后的结果.,简单观察一下,分词后 ,有许多 “在”,”下”,”一”等等无意义的停用词
4.接下来,我们进行专有名词,停用词过滤. 并统计词频.点 功能分析 —词频分析(中文)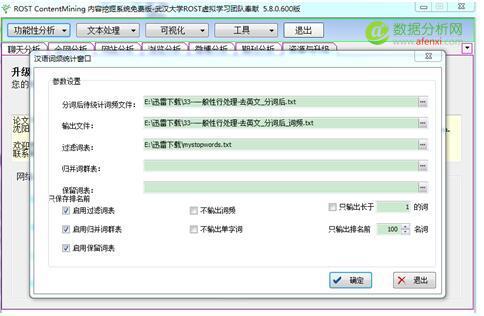
在功能性分析下点情感分析,可以进行情感分析,
并可以实现云图的可视化.
7.2 R的实现
这里需要安装几个必须包,因为有几个包安装比较复杂,这里给了链接http://blog.csdn.net/cl1143015 … 82731
大家可以参看这个博客安装包.安装完成后就可以开始R文本挖掘了
加载工作空间
library(rJava)
library(tmcn)
library(Rwordseg)
library(tm)
setwd(“F:/数据及程序/chapter15/上机实验”)
data1=readLines(“./data/meidi_jd_pos.txt”,encoding = “UTF-8″)
head(data1)
data<-data1[1:100]
—————————————————————#Rwordseg分词
data1_cut=segmentCN(data1,nosymbol=T,returnType=”tm”)
删除 ,英文字母,数字
data1_cut=gsub(“ ”,””,data1_cut)
data1_cut=gsub(“[a-z]*”,””,data1_cut)
data1_cut=gsub(“d+”,””,data1_cut)
write.table(data1_cut,’data1_cut.txt’,row.names = FALSE)
Data1=readLines(‘data1_cut.txt’)
Data1=gsub(‘”‘,”,data1_cut)
length(Data1)
head(Data1)
———————————————————————– #加载工作空间
library(NLP)
library(tm)
library(slam)
library(topicmodels)
R语言环境下的文本可视化及主题分析
setwd(“F:/数据及程序/chapter15/上机实验”)
data1=readLines(“./data/meidi_jd_pos_cut.txt”,encoding = “UTF-8”)
head(data1)
stopwords<- unlist (readLines(“./data/stoplist.txt”,encoding = “UTF-8”))
stopwords = stopwords[611:length(stopwords)]
删除空格、字母
Data1=gsub(“ ”,””,Data1)
Data1=gsub(“[a~z]*”,””,Data1)
Data1=gsub(“d+”,””,Data1)
构建语料库
corpus1 = Corpus(VectorSource(Data1))
corpus1 = tm_map(corpus1,FUN=removeWords,stopwordsCN(stopwords))
建立文档-词条矩阵
sample.dtm1 <- documentTermMatrix(corpus1, control = list(wordLengths = c(2, Inf)))
colnames(as.matrix(sample.dtm1))
tm::findFreqTerms(sample.dtm1,2)
unlist(tm::findAssocs(sample.dtm1,’安装’,0.2))
—————————————————————–
#主题模型分析
Gibbs = LDA(sample.dtm1, k = 3, method = “Gibbs”,control = list(seed = 2015, burnin = 1000,thin = 100, iter = 1000))
最可能的主题文档
Topic1 <- topics(Gibbs, 1)
table(Topic1)
每个Topic前10个Term
Terms1 <- terms(Gibbs, 10)
Terms1
——————————————————————- #用vec方法分词
library(tmcn)
library(tm)
library(Rwordseg)
library(wordcloud)
setwd(“F:/数据及程序/chapter15/上机实验”)
data1=readLines(“./data/meidi_jd_pos.txt”,encoding = “UTF-8”)
d.vec1 <- segmentCN(data1,returnType = “vec”)
wc1=getWordFreq(unlist(d.vec1),onlyCN = TRUE)
wordcloud(wc1$Word,wc1$Freq,col=rainbow(length(wc1$Freq)),min.freq = 1000)
#
8.结果展示与说明
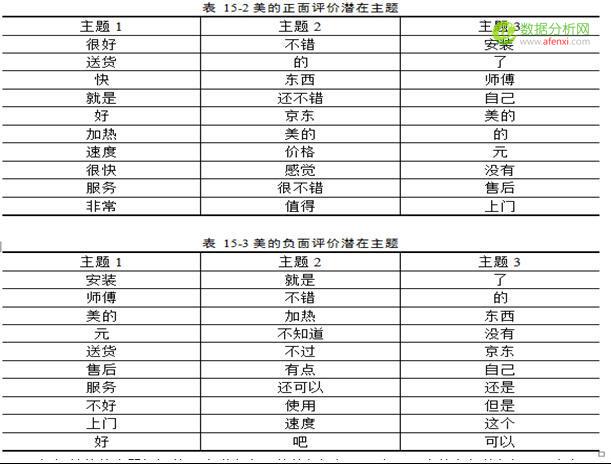
这是分析的部分结果.可以看到大部分客户的评论包含积极情绪,说明了客户对于美的热水器认可度比较高满意度也可以,当然,我们仅凭情感分析的结果是无法看出,客户到底对于哪些方面满意,哪些方面不满意,我们有什么可以保持的地方,又有哪些需要改进的地方,这就需要我们的另一项结果展示.
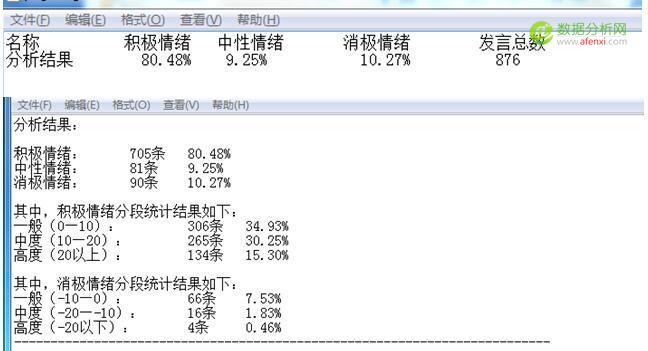

点可视化工具,便可得到词频云图.根据云图,我们可以看到客户最最关心的几个点,也就是评论中,说得比较多的几个点,由图我们可以看到”安装”,”师傅””配件””加热””快””便宜””速度””品牌””京东””送货”“服务””价格””加热”等等关键词出现频率较高,我们大致可以猜测的是26
安装方面的问题
热水器价格方面比较便宜
热水器功能方面 加热快,
京东的服务和送货比较快.
另外值得我们注意的是,云图里面,也有些”好”,”大”,”满意”等等出现比较多的词,我们尚且不知道这些词背后的语义,这就需要我们去找到相应的评论,提取出这些词相应的主题点.再加以优化分析的结果