

本篇论文已被NeurIPS 2024接收,论文第一作者但俊来自浙江大学&FaceChain社区,共一作者刘洋来自伦敦国王学院&FaceChain社区,通讯作者孙佰贵来自阿里巴巴&FaceChain社区,还有合作作者包括帝国理工学院邓健康,FaceChain社区谢昊宇、李思远,伦敦国王学院罗山。

一、前言
在领域,形象的生成需要依赖于基础的表征学习。FaceChain 团队除了在数字人生成领域持续贡献之外,在基础的人脸表征学习领域也一直在进行深入研究。采用了新一代的 Transformer 人脸表征模型 TransFace 后,FaceChain 去年也是推出了 10s 直接推理的人物写真极速生成工作,FaceChain-FACT。继 TransFace 之后,FaceChain 团队最近被机器学习顶级国际会议 NeurIPS 2024 接收了一篇人脸表征学习新作, "TopoFR: A Closer Look at Topology Alignment on Face Recognition",让我们一睹为快。

二、背景
1. 人脸识别
卷积神经网络在自动提取人脸特征并用于人脸识别任务上已经取得了巨大的成功。训练基于卷积神经网络的人脸识别模型的损失函数主要分为以下两种类型:(1)基于 Metric 的损失函数,例如 Triplet loss, Tuplet loss 以及 Center loss。(2) 基于 Margin 的损失函数,例如 ArcFace, CosFace, CurricularFace 与 AdaFace。
相比于基于 Metric 的损失函数, 基于 Margin 的损失函数能够鼓励模型执行更加高效的样本到类别的比较,因此能够促进人脸识别模型取得更好的识别精度。其中,ArcFace 成为业界训练人脸识别模型首选的损失函数。
2. 持续同调
下面介绍一下持续同调与我们方法相关的一些知识。
持续同调是一种计算拓扑学方法,它致力于捕捉 Vietoris-Rips 复形随着尺度参数变化而进化的过程中所呈现的拓扑不变性特征,其主要用于分析复杂点云的潜在拓扑结构。近年来,持续同调技术在信号处理、视频分析、神经科学、疾病诊断以及表征学习策略评估等领域表现出了极大的优势。在机器学习领域,一些研究已经证明了在神经网络训练过程中融入样本的拓扑特征可以有效地提高模型的性能。

三、方法
1. 本文动机
现存的人脸识别工作主要关注于设计更高效的基于 Margin 的损失函数或者更复杂的网络架构,以此来帮助卷积神经网络更好地捕捉细腻度的人脸特征。
近年来,无监督学习和图神经网络的成功已经表明了数据结构在提升模型泛化能力中的重要性。大规模人脸识别数据集中天然地蕴含着丰富的数据结构信息,然而,在人脸识别任务中,目前还没有研究探索过如何挖掘并利用大规模数据集中所蕴含的结构信息来提升人脸识别模型在真实场景中的泛化性能。因此本文致力于将大规模人脸数据集中内在的结构信息注入进隐层空间中,以此来显著提升人脸识别模型在真实场景中的泛化性能。
我们使用持续同调技术调研了现存的基于卷积神经网络的人脸识别模型框架数据结构信息的变化趋势,如图 1 与图 2 所示,并得到了以下三个新颖观测结论:
(i)随着数据量的增大,输入空间的拓扑结构变得越来越复杂
(ii)随着数据量的增大,输入空间与隐层空间的拓扑结构差异越来越大
(iii)随着网络深度的增加,输入空间与隐层空间的拓扑结构差异越来越小,这也揭示了为什么越深的神经网络能够达到越高的人脸识别精度。
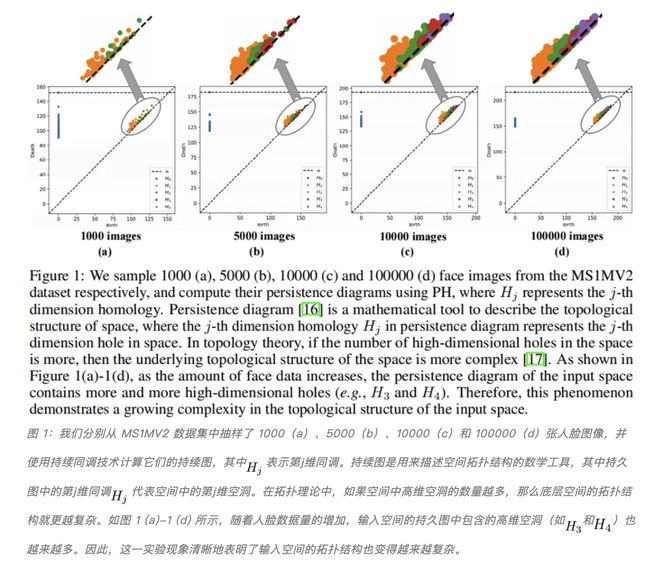
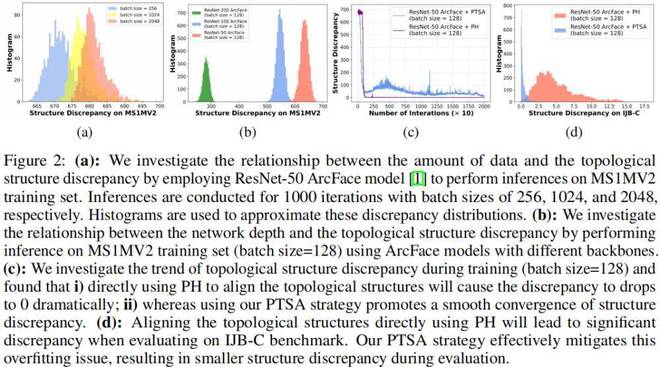
图 2:(a) 我们首先使用基于 ResNet-50 架构的 ArcFace 模型对 MS1MV2 训练集执行推断,以此来探究数据量与拓扑结构差异之间的关系。在推断时,batch-size 被分别设置为 256、1024 和 2048,并分别进行了 1000 次迭代。我们使用直方图来近似这些拓扑结构差异分布。
(b) 其次,我们使用具有不同 ResNet 架构的 ArcFace 模型在 MS1MV2 训练集上进行推断(batch-size=128)以此来研究网络深度与拓扑结构差异之间的关系。
(c) 此外,我们研究了训练过程中拓扑结构差异的变化趋势(批量大小 = 128),发现 i) 直接使用 PH 对齐拓扑结构会导致差异急剧减少至 0,这意味着隐层空间的拓扑结构遭遇了结构崩塌现象;ii) 而我们的 PTSA 策略促进了结构差异的平稳收敛,有效地将输入空间的结构信息注入进隐层空间。
(d) 直接使用 PH 对齐拓扑结构会导致模型在 IJB-C 测试集中出现显著差异。我们的 PTSA 策略有效缓解了这种过拟合问题,在 IJB-C 数据集上评估过程中展现出更小的拓扑结构差异。
基于以上的观测结论,我们可以推断出,在大规模识别数据集上训练人脸识别模型时,人脸数据的结构信息将被严重破坏,这无疑限制了人脸识别模型在真实应用场景中的泛化能力。
因此,本文研究的问题是,在人脸识别模型训练过程中,如何在隐层空间有效地保留输入空间的数据所蕴含的结构信息,以此提升人脸识别模型在真实场景中的泛化性能。
2. 具体策略
2.1 模型的整体架构
针对上述问题,本文从计算拓扑学角度出发,提出了基于拓扑结构对齐的人脸识别新框架 TopoFR,如下图 3 所示。
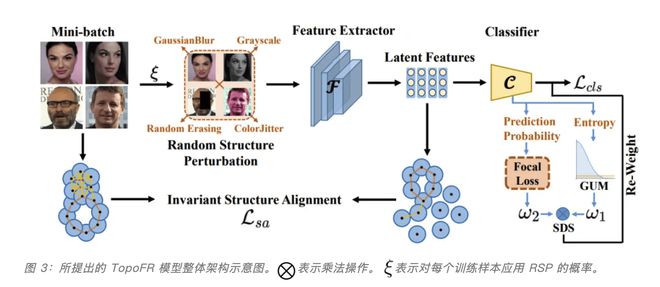
2.2 扰动引导的拓扑结构对齐策略 PTSA
我们发现,直接采用持续同调技术对齐人脸识别模型输入空间和隐层空间的拓扑结构,难以在隐层空间上本质保留输入空间的结构信息,进而容易导致模型的隐层空间遭遇结构崩塌现象。为了解决这个问题,我们提出了扰动引导的拓扑结构对齐策略 PTSA,其包含了两个机制:随机结构扰动 RSP 和 不变性结构对齐 ISA。
随机结构扰动 RSP

2.3 结构破坏性估计 SDE
在实际的人脸识别场景中,训练集通过会包含一些低质量的人脸图像,这也被称为困难样本。这些困难样本在隐层空间中很容易被编码到靠近决策边界附近的异常位置,严重破坏了隐层空间的拓扑结构,并会影响输入空间和隐层空间拓扑结构的对齐。
为了解决这个问题,我们提出了结构破坏性估计策略 SDE 来精准地识别出这些困难样本,并鼓励模型在训练阶段重点学习这些样本,逐渐引导起回归到合理的空间位置上。
预测不确定性
困难样本通常分布在决策边界附近,因此也有着较大的预测不确定性 (即分类器处的预测分布熵较大) ,这也是其容易被错误分类的原因。为精准地筛选出这些困难样本,我们提出利用高斯 - 均匀混合分布概率模型来建模这些样本的预测不确定性,其利用分类器处的预测熵作为概率分布的变量:
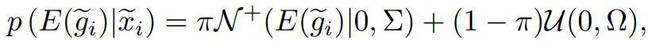


四、关键实验及分析
1.1 训练数据集与测试基准
我们分别采用 MS1MV2 (5.8M 图像,85K 类别),Glint360K (17M 图像,360K 类别) 以及 WebFace42M (42.5M 图像,2M 类别) 作为我们模型的训练集。
利用 LFW, AgeDB-30, CFP-FP, IJB-C 以及 IJB-B 等多个人脸识别测试基准来评估我们模型的识别与泛化性能。
1.2 在 LFW, CFP-FP, AgeDB-30, IJB-C 以及 IJB-B 测试基准上的实验结果
我们可以观察到,TopoFR 在这些简单的基准上的性能几乎达到了饱和,并显著高于对比方法。此外,TopoFR 在不同 ResNet 框架下都取得了 SOTA 性能。值得一提的是,我们基于 ResNet-50 架构的 TopoFR 模型甚至超越了大部分基于 ResNet-100 的竞争者模型。
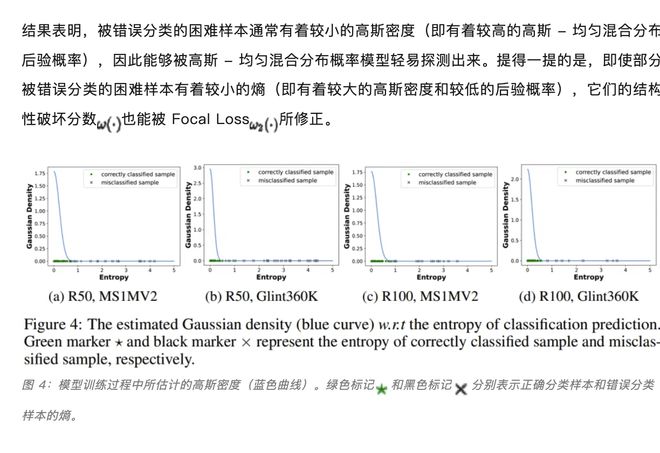
1.3 高斯 - 均匀混合分布概率模型的有效性
为验证高斯 - 均匀混合分布概率模型在挖掘困难样本方面的有效性,我们展示了模型训练过程中利用分类器预测熵所估计的高斯分布密度函数,如下图 4 所示。
1.4 扰动引导的拓扑结构对齐策略的泛化性能
为表明此拓扑结构对齐策略 PTSA 在保持数据结构信息方面的一流泛化性能,我们在 IJB-C 测试集上调查了 TopoFR 模型与其变体 TopoFR-A 在输入空间与隐层空间上的拓扑结构差异,如下图 5 所示。值得一提的是,变体 TopoFR-A 直接利用持续同调技术来对齐两个空间的拓扑结构。
所得到的可视化统计结果明显地表明了我们所提出的扰动引导的拓扑结构对齐策略 PTSA 在保留数据结构信息方面的有效性和泛化性。
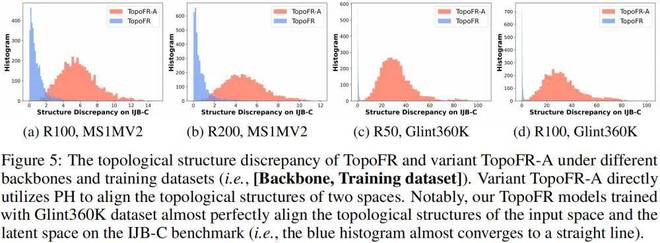
图 5:TopoFR 和变体 TopoFR-A 在不同网络主干架构和训练数据集上的拓扑结构差异 [网络主干架构,训练数据集]。变体 TopoFR-A 直接利用持续同调技术对齐两个空间的拓扑结构。值得注意的是,我们使用 Glint360K 数据集训练的 TopoFR 模型在 IJB-C 测试集上几乎完美地对齐了输入空间和隐层空间的拓扑结构(即蓝色直方图几乎收敛为一条直线)。
五、结论