

请不要读这个专业!!!!!!

因为你拼不过那群学CS的,而且在国内严重的溢价
直接去读计算机吧,没事读什么统计,面试只会问你代码敲的咋样,你搞了一堆建模,关心的其实是你会不会SQL,Hive这类数据仓库的工具,简而言之就是...
统计学生一般想走的是数据科学家的路线,但...市场更多的需求是数据工程师,简而言之...这专业目前并不容易找到符合成长规划的职位
今年央财复试线421,70+70+140+140=420都上不了岸。而且虽然初试只考概率统计,复试还是要考一堆多元分析,时间序列或者偏大数据的数据结构等科目。还敢考的都是勇士中的勇士,只能说应统上岸的都是卷王中的卷王。有这卷的精力早点去准备计算机的专业课不行吗,计算机和统计相比出路还是好太多。
统计的就业面是广,但是广意味着不精,在市场的就业量都是零零星星的。在大家认知中属于统计范畴的专业,数据分析其实是不限专业的,数据科学家更别说了主要是cs那块的,你去做量化做商业分析,招人的数量比码农少一个level不说,金融和咨询公司都是很卡学历的,清北复交才比较能在这行吃的开。
统计这几年的考研录取分数线已经溢价严重了,虽然目前热度没有消退的痕迹,但其回归正常价值水平是迟早的事。
本人本科某一线城市211大学统计学,保研本校应用统计硕士,个人已经毕业,后文我说一下周围人的出路。
目前形势是:私企太累,很多都是单休、压榨、内斗、职场pua。学统计的确实脑子聪明,每天都是上演宫斗剧一样。
公务员:统计相关报录比一比几千。。。这概率。。。(我没考,我从网上看的)
我本人是毕业去了大型上市名企做数据分析,身体累心里累,内斗严重,办公室政治、小团体……
我个人经历的职场里面大家的学历都还不错,但是很多人素质真的是恶心到想吐,不光我们数据分析岗,周围的人都是油嘴滑舌、狐狸精、蛮横刁钻的人,毕竟职场很残酷,大家都为自己的晋升、涨工资着想,每天都是明争暗斗、勾心斗角。领导们都非常的刻薄,嘴毒,员工整体年纪不大,口头上说要贯彻扁平化管理,但最后个个都成了官僚的继承者,但是一堆所谓的领导喜欢搞形式、等级,明面上关爱员工,实际上领导们背后一套又一套损招,可算是见识了职场的残酷无情,画大饼,想方设法榨取你所有的劳动力,薪资和付出和当前房价啥的都完全不成正比。
----小小更新一下----
我把个人经历时间线简单更新一下:
统计学本科→应统保研→数据分析实习→数据分析全职→考教师证→公立初中数学老师。
感慨一下,还是学生时代最单纯最幸福。
工作一段时间后,我的想法是考教师证、辞职、打算进中学当数学老师。因为本硕不是纯数学师范专业出身,所以进高中有点难,但是进初中比较容易一些。当老师也有压力,但是相对来说算工作环境惬意一些了。
其他应用统计研究生舍友出路:
舍友1:毕业考公,听说报录比1:1800,没考上。英语还不错所以去了外贸公司做服装销售,单休,但是一开始入职有一周的无薪试岗,相当于白给资本家打工。总体这份工作是多劳多得,销售量高工资也跟着涨,低底薪高提成。
舍友2:回了新疆老家当高中数学老师,大多数时候双休。工资低,但是有寒暑假,法定节假日也能休息,个人时间多。高三班要周末补课,舍友说可能会变成单休,总的来说工作比较稳定,听说个人精力充沛的话还能做家教兼职之类的工作。
舍友3:私企里转行做人事专员,工作不算累,胜在相对清闲,不太费脑子,工资不高,单休,五险入职半年后表现优异者给交,但公积金公司不提供。
舍友4:去了大厂互联网做数据分析,偏电商行业,单休,996无加班费,她公司试用期不给交五险。每天看运营和市场部领导的脸色,工作饱和度高,很累,没个人时间,压力较大,但是能学到东西,做得好会有绩效奖金,舍友说奖金被压得超低,工作付出和薪酬不成正比,kpi极其苛刻,随着各线上购物节的非常乐观的营收,舍友的公司业绩越来越好,但是工资却一直不给涨,一提加薪就给画大饼打感情牌。
舍友5:国有银行做财务分析,双休,但是全员营销的模式,喊口号,军训,跳营销舞,晨会,平时还得陪销售人员拉客户,做推广。完不成全员销售任务罚做值日超级辛苦。优点是加班不多,五险一金正常交。
师姐1:比我大一届的师姐,人很nice也是保研的,读书的时候在一家户外运动用品公司做销售数据分析实习,毕业后在一家汽车配件公司担任文员兼数据分析,主要是记录销售数据,提交分析报告,不太需要用到编程,工作低薪且辛苦。名义上双休,但是师姐说领导很恶心,搞加班文化,周六没工作但不让休息,搞企业军训,喊效忠口号,单休周日,而且在职期间逼签各种霸王协议,办公室还有很多肢体、言语暴力,气氛非常压抑。师姐好在家里有一定的积蓄,辞职后加盟了一家童装店,算是转行创业了。
师兄1:比我大一届,读书的时候在一家k12互联网教育公司做数据分析实习,但是不提供转正的机会。师兄后来毕业考了事业单位,具体是哪个单位和岗位我都不清楚,因为后续没再跟师兄联络,反正报考的岗位和数据分析没有关系,也算转行。事业单位薪资可能明显偏低,但是胜在稳定,而且有双休+社保。
---------2021.6.04补充---------
我跟上述的舍友4近期约了饭,舍友4虽然当时公司给她上了社保,但是后来公司又以其他理由再次拖欠她的社保,她们hr说是只有经理级别以上才配交社保,其他级别的员工暂时不参保,而且还给舍友洗脑说社保无用之类的话,公司不交社保是为了通过压榨劳动权益来降低运营成本。舍友4曾经申请了劳动监察+劳动仲裁,最后赢回了自己应该享有的劳动权利!!!
我借上述案例给师弟师妹们提个醒,社保是一入职就要缴纳的,是公司的义务!!!
那些转正后才交社保,或者一年后再交,或者升职后再交的都是违反劳动法!!!!
资本家都是为了降低公司运营成本特别不愿意给员工交社保,见了这种公司你们一定要远离。
然后必要的时候给自己维权!!!争取合法权益!!!
我们是211大学,舍友们毕业去的都是知名大公司,但是大厂的劳动保障也不一定完善,进去后能收获工作技能积累经验,但却不一定能拿到该享有的工作保障,资本家个个都精打细算,招聘压薪、降薪、违法辞退、不交社保、不签劳动合同、合同玩文字游戏、合同玩霸王条款、双休变单休、加班无加班费、画饼、打感情牌、讲情怀不讲薪资、拖欠工资、压绩效与提成、恶意罚款扣工资……,反正怎么省钱就怎么来,很多公司在劳动保障方面一点都不靠谱,大厂也有很多劳动仲裁的案例,企查查、天眼查一查就能查出来。总之就是大公司和小公司一样不靠谱,大家求职一定要擦亮眼睛!只要有资本家的地方永远都有无形的压榨。
反正现在工作大环境就是:如果想找个社保公积金合法缴纳+固定双休的工作,估计也真的只能去公务单位、央企、事业单位了。如果想在私企找到这样待遇的工作真的比登天还难。
-----
言归正传:反正就是应用统计跟冷门理工和人文社科比起来,技能型更高,算是一技之长。
但是也有一定中庸性,比如搞金融拼不过金融经济出身的、搞信息技术拼不过cs出身的。
如果你对统计、数据分析感兴趣的话,也可以试试这个专业,欢迎来,但是也需要做好一定思想准备,现在知乎上不都流行一句话——选择大于努力,所以选择也是很重要的,应统确实竞争到爆。
本科应统毕业来答一波
转行去了数理金融。应统专硕实在是太卷了_(:* 」∠)_,卷到崩溃。
出成绩的那几天,一直有人来问我跨考应统专硕的事,在很多人心中就自然的认为统计学和大数据是一回事,实则不然,统计学在国外很多会叫作统计与运筹学,国内统计学发展还处于起步阶段,各个学校的培养计划都不尽相同,基本都处于摸着石头过河的状态。我本科学校是商科学校,所以就会学很多偏经济类的课,毕业后很多人会直接去银行工作(因此被调侃成定向输送银行专业)。
应统考研竞争激烈的一大部分原因,我认为是这个专硕的门槛太低了(英二➕数三➕统计学),这个数学加英语的组合吸引了一大批人前来跨考,分数自然水涨船高。尤其是这个数三,直接把应统专硕定位到经济管理方面的学科之中,要知道在我们学校,我们专业大一时候的培养方案是和数学系一致的(直接数分高代解析几何,大三的时候还要学常微分。微积分函数线代啥的都没有),本专业的学生如果数学底子不好的话,后面的专业课真的很难理解(考研复试的时候就会看到一大堆五花八门的专业课,多元时序抽样随机啥的)
还有给大家澄清一波,
统计学不是大数据!
统计学不是大数据!
统计学不是大数据!
之前可能在国内关于统计学的言论导向有些偏差,严格的说,大数据需要统计学基础,但不是全部。毕业校招那会,我室友拿着一叠简历转了一圈就回来了,很多岗位会要求熟练使用python,c,java,sql之类的,but我们专业只会学学r,sas,stata之类的统计软件,再多点就学学matlab,很难符合要求。在大数据里,统计学是方法,cs是实践,不会cs就很难做出来东西空有一肚子理论。从这点来讲,大数据和数学系的信息与计算科学专业有点类似。
更新,工作五年了(2023年四月离职),之前说怎么都不会换工作还是换了,新工作不加班(早十晚七),还是分析岗不过不是数据中台,工资待遇也高了,加上自媒体应该快过百了
回首过去,我只是个普通的统计学生,赶上这趟车只是运气,只是有着一门赚钱心思的俗人。现在的同学,我觉得没必要盯着某个岗位或者某个行业,而是要在明确当前情况的前提下自己做出选择,市场上有很多数据分析培训班,但是也逐渐落后于时代了。
数据分析需要系统化学习、进阶需要不断地学习和实战,为此渭河建立了一个分享社区,有经验丰富的大佬分享干货、解答问题,也有许多小伙伴交流讨论,目前已经有近700名分析师加入。感兴趣的同学可以点击链接了解:渭河原创百万字知识库-千名用户-零基础入门-分析进阶-未来发展-职场分享
ps:学生永远半价
更新,工作已经4年了,薪资水平还是比较令人满意的,至少不管怎么样,可能我都不会换工作。
但是另一边随着互联网的一个衰退,还有数据分析师岗位竞争的激烈,这个专业可以说是比去年回答的时候还要卷。
而且即使是读了应用统计,也很难找到数据分析师的工作,主要是他确实性价比太高了,竞争很激烈,但是如果你卷赢了,这个薪资水平是真的香,今年top9的应统硕士去大厂或者通讯龙头拿数分或者战略的offer依然可以开30w+的薪资,但是需求大量减少是事实,换句话说,这些人五年前入行可能拿的更高
数据分析师可以拿多少薪资?以下是原回答,每年给你们更新一下工作情况好吧:
近几年应用统计的专业是越来越卷了。
985本工作三年数分小白来回答一下。
不知道为什么最近这个问题浏览量那么高
但我看下来居然没有站应统的,就很奇怪
那么多人都冲去考研,现在有一堆人告诉你,别去了,去了也没用,人家火都是人家傻,其实没什么好学的。
难道不矛盾么?
其实现在抛开程序员,或者说前后端不谈,数分确实是一个后来居上的岗位。不说我自己,身边应统毕业的同学,基本都在15k以上的应届薪资,比我当年要高了不少。整个岗位的发展很有前景,薪资也很有想象力。
重点是:最适合这个岗位的就是应用统计。
或者以后会发展成大数据或者数据科学,但是目前来看,如果有候选人各方面能力相同,专业不同,我会优先看应用统计的同学。
薪资是一方面,但也不会尬吹应统,只是希望大家找到自己适合的方向。总有人不喜欢做前端,或者不合适做程序员,做cs的,那么应统是比较好的学科,也是stem的课程重点。
应统的好处在于:弥补理科知识的短板,如果你是cs本科,以后想做数据科学,数据分析,挖掘,算法,商业分析等岗位,选择应统再好不过。
如果你本身就是统计出身,并且觉得自己并不喜欢编程和做程序员,对产品,设计等岗位没感觉,那也建议学应统,也就是学一下sql和python,这个一个月就能搞定,搞不定的看我写的文章。
如果你不是统计,也不是cs出身,你想涉足互联网,但又没有足够的计算机知识,那也建议学统计。他不仅有数理知识,也会教你简单的统计软件,不管你以后做运营,管培,统计都对你有好处。
综上,其实统计会是很多人的选择,不是说感觉学统计不如学cs,至少我们去招数据分析师,看中的更是分析的思路而非软件的使用,不是你精通各种软件就可以的。
还有一点是职业性格,不是所有人都适合cs,我个人感觉,学的进cs的至少是有钻研精神的人,能耐得住寂寞的人,我就不太属于。
相比之下,数据分析师更需要很多沟通技巧,数据可视化技巧,需要去说服人,是让数据不再冰冷的一个岗位。如果你觉得你是这种人,去测试一下你的职业性格,再来选择专业。
最后最后,对于统计的就业结果,我只能说,待遇上弱于程序员,高于运营,与产品相当。工作环境比程序员和运营好,和产品相当。大概是这样。
最后最后最后,要劝退各位的一点,那就是做分析岗很看重分析,分析思路不是容易习得的技巧,而是要在不断锤炼下得来的思考习惯,数据分析一定是主动的,积极的岗位,即使做到数挖和算法也是如此。
如果想要做数分的可以参考下面的帖子
【干货】学生党的数据分析指南- 想要了解互联网公司招聘的一些诀窍,可以登牛客网上去看一看。我从入行的时候就一直在看,里面包括各公司的一些信息,还有一些面试经验模拟面试各种面经,还有各种模拟代码环境(SQL,python,java,c),可以说是it从业者必备
- 可以使用下方链接快速注册哦
希望对各位同学有个帮助哦~
百度统计,友盟+都是挂网站统计的平台,然而这两个平台的操作稍有复杂,而且对于大多数用户没有收益。
但其实 百度统计、友盟+为他们大数据提供信息参数+相当于‘余额宝’把钱借给‘银行’每日访问超过5000万IP可申请
这个合作门槛让很多站长达不到,所以一个聚沙成塔效应的联盟出现了百度与友盟+给联盟钱联盟再给你们钱效果跟你们自己挂统计一样这就是一个挂统计就给钱的联盟
无任何广告,小程序或页面弹出,就是提供网站的统计即可。
挂统计赚钱联盟点此进入
方法也很简单。
怎么样?想试试这个认知以外的钱吗?满1元即可支付哦!
小Z来自荐一下~
Zoho PageSense是一款可以帮助您分析网站数据,了解访客在线行为,为访客提供个性化的网站体验,从而提高线索转化率的网站优化工具。
近日,有网友向百度提问网站统计工具piwik的退出率、跳出率、浏览量的定义,百度百科将对这三个概念进行说明。
1:网站统计的目的
统计工具piwik可以帮助网站管理员更好地了解用户的浏览习惯,从而制定更有针对性的网站运营策略。
2:piwik的退出率、跳出率、浏览量定义
网站统计工具piwik,退出率、跳出率、浏览量的定义?1. 退出率是指访问者在浏览网站时离开网站的页面数量与总访问页面数量之比。2. 跳出率是指访问者在浏览网站时离开网站的页面数量与总浏览页面数量之比。3. 浏览量是指访问者在浏览网站时浏览的页面数量。
3:如何降低piwik的退出率、跳出率、浏览量
降低piwik的退出率、跳出率、浏览量的方法有很多,首先要明白它们的含义。piwik的退出率是指访问者在浏览网站后直接离开的比例,跳出率则是指访问者在浏览网站后浏览一个页面就离开的比例。浏览量则是指访问者在浏览网站时查看页面的次数。要想降低piwik的退出率、跳出率、浏览量,首先要做的就是了解访问者的需求,根据他们的需求来设计网站的内容和结构。另外,还要注意网站的加载速度,让访问者能够快速浏览网站。
以上就是关于网站统计工具piwik的退出率、跳出率、浏览量的定义,希望能够帮助到网友。
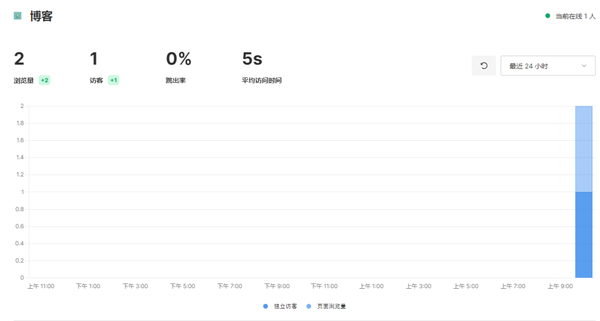
这个项目是经过自己实践过的,如果你有自己的网站或者是博客以及小站点的话,推荐你自己搭建一个属于自己的统计网站。
原始的教程:https://zuofei.net/5018.html
我就是看他的教程学会的,其实这个教程很简单。只要仔细的多看几遍就会了。
就和原来的博主所说的一样,我也用过谷歌分析、51la、百度统计等,对于我来说这些都东西都是太复杂了,而且它们的界面不是我喜欢的类型。
今天需要用的到几个网站是:Vercel、Supabase、Umami
这3个网站都是可以在谷歌浏览器上直接搜索出来的。我就将这个3个网站直接贴出来,直接复制到浏览器即可。
https://supabase.com/
https://vercel.com/
https://github.com/umami-software/umami
最重要的就是 Umami 这个github项目。
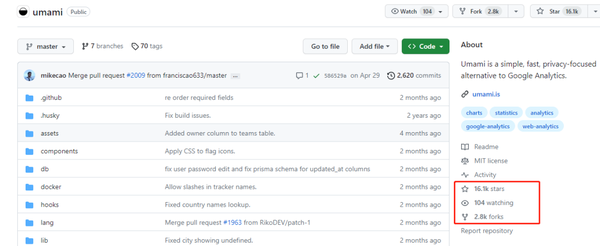
这个项目有 16.1k stars 以及 2.8k forks。
好,开始整。
1、首先在 Supabase 建立数据库
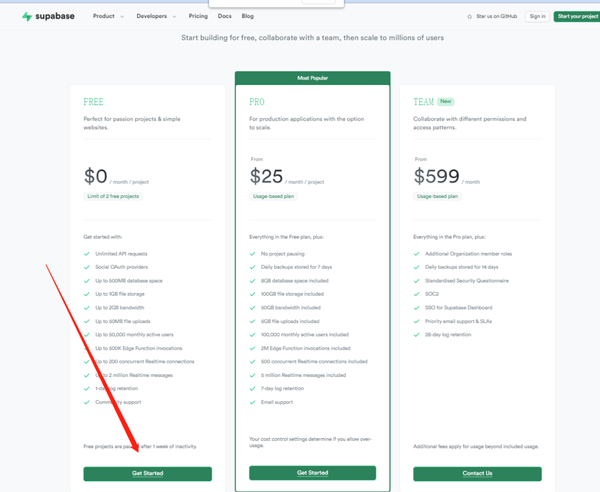
在 Supabase 官网上选择免费方案,点击开始之后,来到登录的页面,直接选择 github 登录。没有账号的可以先去创建github账号。
之后进入到创建项目的页面,按照相关的要求填写即可,名字随便填写,数据库密码自己随便填写,但是需要记得,等下需要用上,也可以用谷歌浏览器自动生成的密码。也可以点击下面的 Generate a password 将生成的密码复制下来。
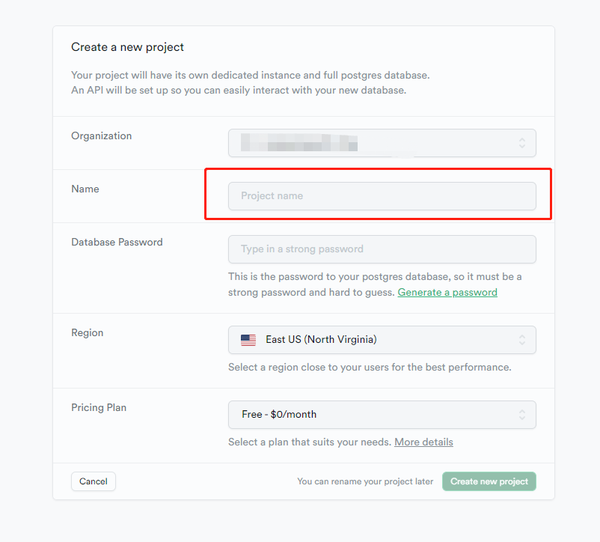
密码填好之后,点击创建项目,等个十几秒项目就创建好了。创建好之后,点击项目管理,然后点击数据库,找到 Connection string 中的URL栏目,复制内容,将 [YOUR-PASSWORD] 换成你刚才生成的密码,记得将括号去掉,直接填写密码, 就生成了一个新的链接。
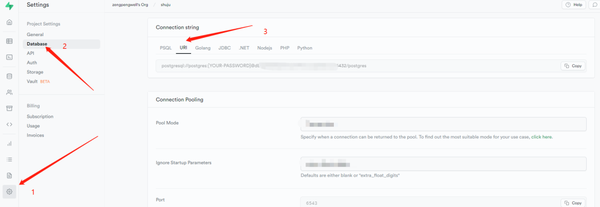
好了,在这个平台的操作就完成了。
2、在 Vercel 上部署 Umami
vercel 这个工具算是老朋友了,之前也是在这个工具上部署过其他的项目。首先也是登录这个网站,之后点击创建项目,之后来到一个新的页面
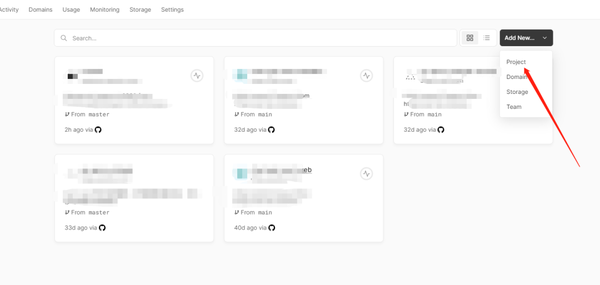
然后再看看你的也页面是否有这个项目。如果没有的话就去 github上 forks。
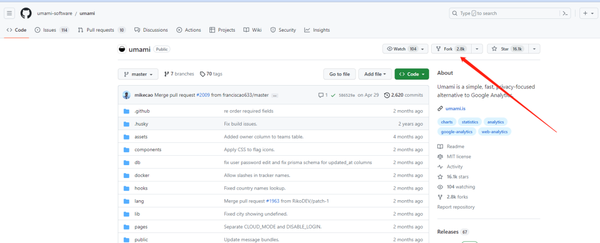
之后点击 import
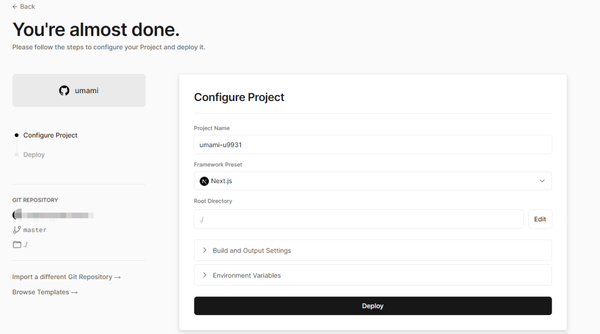
配置环境变量
在这里需要配置分别添加 DATAbase_URL 和 HASH_SALT。前者是上一步在 Supabase 复制的 URL,记得替换自己的 Password;后者需要自己随意生成一长串字符串自己随便填写也是可以的。最后点击 Deploy。之后等待几分钟就可以了
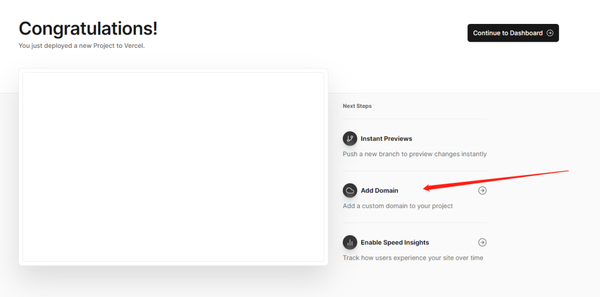
创建好之后来到这个页面,这个时候差不多就创建成功了。之后就是绑定域名和将跟踪代码放到网站上去。点击添加域名。
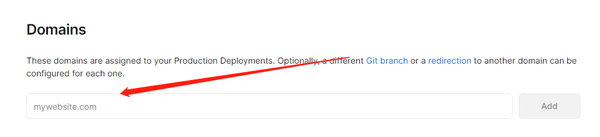
这里一般都是填二级域名,二级域名的解析一般是 CNAME 解析,记录值填写 Vercel 给的就可以。之后等待几分钟就可以访问你的统计网站了。
3、使用 Umami
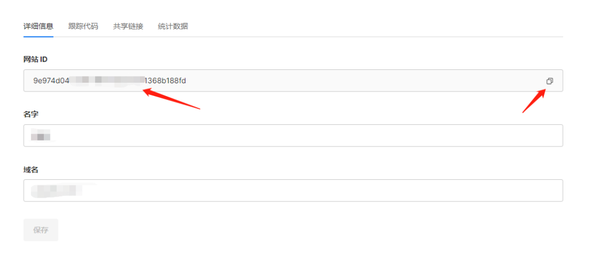
按照上面的步骤操作基本上就能创建好一个属于自己的统计网站,通过绑定的域名进入网站。默认的用户名和密码分别是 admin 和 Umami 进入后台之后先去改密码。改完密码之后就可以绑定自己的网站。
添加之后点击编辑,点击跟踪代码,复制这串代码。
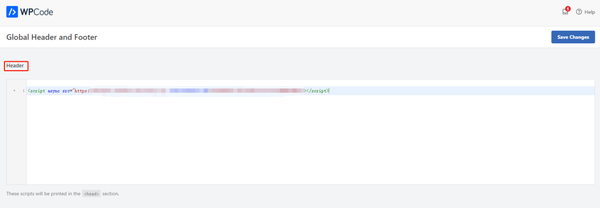
之后来到 wordpress 的后台,你可以直接在网站的主题上加上这段代码。我个人是比较倾向于用插件加代码。安装 WPCode Lite 这个插件之后将跟踪代码复制到页头代码处。
这样就安装好了,之后就可以通过你自己搭建的统计网站,查看你自己的网站的数据了。
以上就是搭建一个统计网站的全部教程,如果你遇上可以可以发消息给我。希望能帮助到你。
1.背景
页面停留时间(Time on Page)简称 Tp,是网站分析中很常见的一个指标,用于反映用户在某些页面上停留时间的长短,传统的Tp统计方法会存在一定的统计盲区,比如无法监控单页应用,没有考虑用户切换Tab、最小化窗口等操作场景。基于上述背景,重新调研和实现了精确统计页面停留时长的方案,需要 兼容单页应用和多页应用,并且不耦合或入侵业务代码。
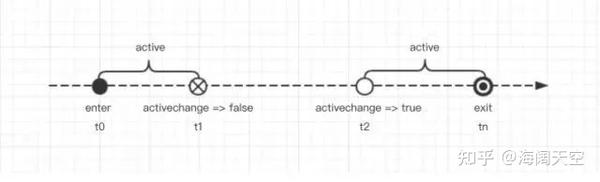
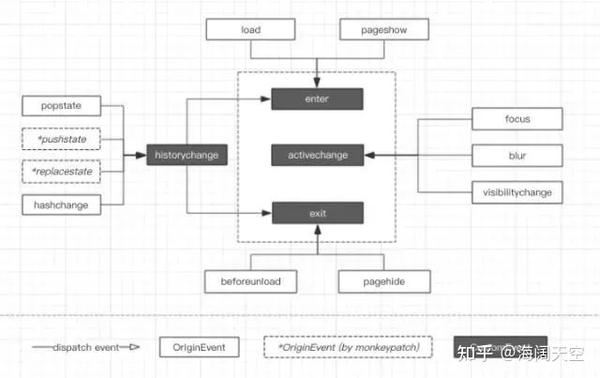
我们可以把一个页面生命周期抽象为三个动作:「进入」、「活跃状态切换」、「离开」
如下图,计算页面停留时长既如何监控这三个动作,然后在对应触发的事件中记录时间戳,比如要统计活跃停留时长就把 active 区间相加即可,要统计总时长既 tn -t0 。
对于常规页面的 首次加载、页面关闭、刷新 等操作都可以通过 window.onload 和 window.onbeforeunload 事件来监听页面进入和离开,浏览器前进后退可以通过 pageshow 和 pagehide 处理。
- load / beforeunload
- pageshow / pagehide
对于单页应用内部的跳转可以转化为两个问题:
- 监听路由变化
- 判断变化的URL是否为不同页面 。
2.1.1 监听路由变化
目前主流的单页应用大部分都是基于 browserHistory (history api) 或者 hashHistory 来做路由处理,我们可以通过监听路由变化来判断页面是否有可能切换。注意是有可能切换,因为URL发生变化不代表页面一定切换,具体的路由配置是由业务决定的(既URL和页面的匹配规则)。
browserHistory
路由的变化本质都会调用 History.pushState() 或 History.replaceState() ,能监听到这两个事件就能知道。通过 popstate 事件能解决一半问题,因为 popstate 只会在浏览器前进后退的时候触发,当调用 history.pushState() or history.replaceState() 的时候并不会触发。
The popstate event is fired when the active history entry changes. If the history entry being activated was created by a call to history.pushState() or was affected by a call to history.replaceState(), the popstate event’s state property contains a copy of the history entry’s state object.Note that just calling history.pushState() or history.replaceState() won’t trigger apopstateevent. The popstate event will be triggered by doing a browser action such as a click on the back or forward button (or calling。history.back() or history.forward() in Javascript).
这里需要通过猴子补丁(Monkeypatch)解决,运行时重写 history.pushState 和 history.replaceState 方法:
let _wr = function (type) {
let orig = window.history[type]
return function () {
let rv = orig.apply(this, arguments)
let e = new Event(type.toLowerCase())
e.arguments = arguments
window.dispatchEvent(e)
return rv
}
}
window.history.pushState = _wr('pushState')
window.history.replaceState = _wr('replaceState')
window.addEventListener('pushstate', function (event) {})
window.addEventListener('replacestate', function (event) {})hashHistory
hashHistory 的实现是基于 hash 的变化,hash 的变化可以通过 hashchange 来监听
2.1.2 判断URL是否为不同页面
方案1: 客户端定义
通过业务方在初始化的时候配置页面规则,然后JS通过URL匹配不同的规则来区分不同的页面,这种方案在客户端数据上报的时候就已经明确了不同的页面,伪代码:
new Tracer({
rules: [
{ path: '/index' },
{ path: '/detail/:id' },
{ path: '/user', query: {tab: 'profile'} }
]
)方案2: 数据分析平台定义
假设我们最终上报后有一个数据分析平台来展现,我们可以在类似数据平台来配置页面规则,这样在客户端实现的代码逻辑就不需要区分页面,而是每次URL发生变化就将数据上报,最终通过数据平台配置的页面URL规则来求和、过滤数据等。
当数据展现平台不支持配置URL规则来区分页面的时候,可以采用方案1;当有数据平台支持的时候采用方案2更合理;
2.1.3 对于页面进入和离开相关事件整理
可以通过 Page Visibility API 以及在 window 上声明 onblur/onfocus 事件来处理。
2.2.1 Page Visibility API
一个网页的可见状态可以通过 Page Visibility API 获取,比如当用户 切换浏览器Tab、最小化窗口、电脑睡眠 的时候,系统API会派发一个当前页面可见状态变化的 visibilitychange 事件,然后在事件绑定函数中通过 document.hidden 或者 document.visibilityState 读取当前状态。
document.addEventListener('visibilitychange', function (event) {
console.log(document.hidden, document.visibilityState)
})2.2.2 onblur/onfocus
可以通过 Page Visibility API 以及在 window 上声明 onblur/onfocus 事件来处理。对于PC端来说,除了监听上述相关事件外,还可以考虑监听鼠标行为,比如当一定时间内鼠标没有操作则认为用户处于非活跃状态。
2.3.1 页面离开时上报
对于页面刷新或者关闭窗口触发的操作可能会造成数据丢失
2.3.2 下次打开页面时上报
会丢失历史访问记录中的最后一个页面数据
目前采用的方案2,对于单页内部跳转是即时上报,对于单页/多页应用触发 window.onbeforeunload 事件的时候会把当前页面数据暂存在 localStorage 中,当用户下次进入页面的时候会把暂存数据上报。有个细节问题,如果用户下次打开页面是在第二天,对于统计当天的活跃时长会有一定的误差,所以在数据上报的同时会把该条数据的页面进入时间/离开时间带上。
Tracer
核心类,用来实例化一个监控,对原生事件和自定义事件的封装,监听 enter activechange exit 事件来操作当前 Page 实例。
P.S. 取名来自暴雪旗下游戏守望先锋英雄猎空(Tracer),直译为:追踪者。
Page页面的抽象类,用来实例化一个页面,封装了 enter exit active inactive 等操作,内部通过 state 属性来维护当前页面状态。
Desktop
Mobile

对于页面停留时长的定义可能在不同场景会有差异,比如内部业务系统或者OA系统,产品可能更关心用户在页面的活跃时长;而对于资讯类型的产品,页面可见时长会更有价值。单一的数据对业务分析是有限的,所以在具体的代码实过程中我们会把停留时长分三个指标,这样能更好的帮助产品/运营分析。
- active 页面活跃时长
- visible 页面可见时长 //仅支持Desktop
- duration 页面总停留时长
之前给大家安利了一款网站搜索软件,可以搜索自己想要的网站,可惜软件只支持安卓,让IOS用户尝不到甜头。前几天逛某论坛的时候,发现了一款增强版搜索神器,使用了一段时间,体验极佳。目前属于内测,不知道后面流量起来了会不会收费。
最香的竟然是网页端使用,不管是PC/安卓/IOS都能直达站点,一款网站聚合搜索引擎神器,搜索你想要搜索到的网站。当然了我们说的是合法合规的网站。
目前收集了全网9百40多万条站点信息,定时收集新运营站点,站点每日搜索次数达20万,每日活跃流量保持在10多万。
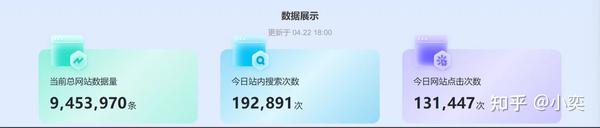
功能包含自定义搜索、自行筛选、站点详细信息、相似站点推荐、站点的流量以及权重。
自定义搜索
测试了游戏、考研、学习、电影、小说、动漫、就没有你搜索不到的网站,呈现的站点一键触达,如有进不去的站点建议切换浏览器尝试。
我之前提到了开发者秘籍,如下所示:

我刚完成第9项目后我突发奇想,如何知道每天到底增加了多少用户?
如果我推广产品后,如何知道推广的效果?
简单来说,就是我该如何统计网页访问量?
我思考了一下,如果要自己实现的话,有以下步骤要做:
- 开发一个统计接口
- 通过 js 发送 ajax 请求到这个接口
- 服务器通过请求头数据对客户端类型、ip进行统计
- 开发一个统计分析管理界面
这些步骤至少要话一个礼拜去实现。
我搜索后,发现了一个非常简单的方案,那就是使用百度统计即可。
步骤很简单,如下:
1.登录百度统计
2.创建网站项目
3.将统计代码嵌入网页
4.验证网页可行性
5.查看界面统计
地址:https://tongji.baidu.com/
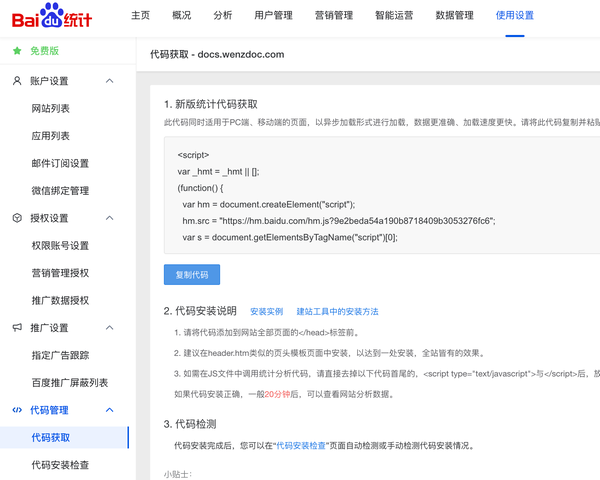
点击左侧“代码获取”,然后点击“复制代码”,如下图:
将代码嵌入到网页中后,可以通过浏览器打开网页源码查看网页是否成功嵌入代码,如下图所示:
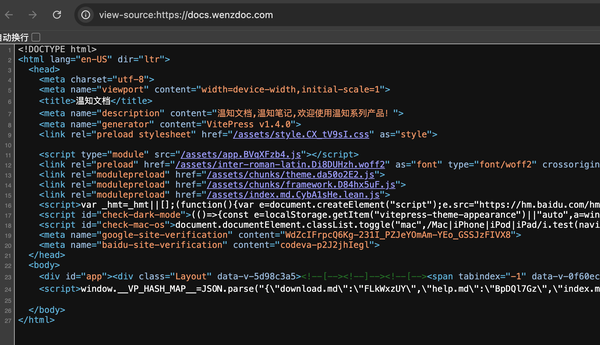
可以看到多了一个script标签,内容就是从百度统计复制的代码。
然后点击“代码安装检查”,就可以看到网站是否成功安装:

可以看到,结果为“代码安装正确”则说明安装成功。
然后就可以在概况中查看访问统计了,如下图所示:
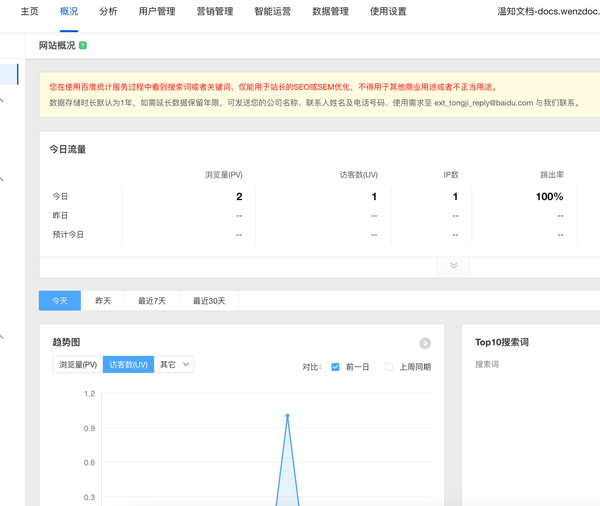
自己做网站统计会比较麻烦,而且还没有百度或者谷歌统计做的好,使用成熟的网页统计方案,可以快速对网站进行统计,可以分析自己每天到底吸引了多少用户。
百度统计原理其实也很简单,就是用js脚本,向服务器发送统计请求,然后就可以记录访问者ip了。