

版权声明:本文为博主AzureSky原创文章,转载请注明出处:http://www.cnblogs.com/jiayongji/p/7420915.html

每年我国政府都会发布年度政府工作报告,而报告中出现最多的TopN关键词都会成为媒体热议的焦点,更是体现了过去一年和未来政府工作的重点和趋势。
在中央政府网站上也可以看到从1954年至今每年的政府工作报告,链接:http://www.gov.cn/guoqing/2006-02/16/content_2616810.htm
那么突发奇想,从这60多年间的政府工作报告中可以看出来什么样的变迁呢?说干就干,下面就是实现这一想法的历程。
-
获取1954年至今历年政府工作报告的全文,并统计出每年政府工作报告中Top20的关键词,并用图表可视化展示出来。
-
统计每十年的政府工作报告的合并Top20关键词,并用图表直观展示出来,从中分析出变迁的趋势。
数据获取阶段需要有两个准备:
- 网页链接:
2017年政府工作报告链接:http://www.gov.cn/premier/2017-03/16/content_5177940.htm
1954~2017年政府工作报告汇总页面链接:http://www.gov.cn/guoqing/2006-02/16/content_2616810.htm
- 技术准备
使用非常好用的web库——requests获取网页内容。
使用BeautifulSoup库解析网页HTML内容,从中解析出政府工作报告的文本内容。
使用结巴分词库(jieba)对政府工作报告文本内容进行分词、过滤无效词、统计词频。
使用matplotlib库画出每十年政府工作报告关键词的散点分布图,通过对比不同年代的图,分析其中的变化趋势。
准备工作做好后,我们开始按照计划一步步地开始实施。
为了代码复用,创建一个html_utils.py文件,提供下载网页内容的函数,并提供了一个HTML页面解析异常类:
我们的总体思路是先获取网页内容,然后从网页内容中解析出政府工作报告正文,然后对其进行分词,这里分词需要用到jieba模块,我们创建一个cut_text_utils.py文件,在其中提供分词的函数,内容如下:
运行上述Demo脚本,输出:
[(u'参观', 1), (u'北京故宫博物院', 1), (u'一起', 1), (u'女朋友', 1), (u'闲逛', 1)]
最终要使用matplotlib库绘出关键词的散点图,可以更直观地进行分析,所以我们再写一个绘图工具文件visual_utils.py,内容如下:
运行上面的Demo脚本,绘图结果如下:
接下来我们先获取到2017年的政府工作报告试试水,创建一个文件year2017_analysis.py,内容如下:
运行上述脚本,然后在当前目录下可以看到产生了一个out.tmp文件,其内容如下:
[(u'发展', 125), (u'改革', 68), (u'推进', 65), (u'建设', 54), (u'经济', 52), (u'加强', 45), (u'推动', 42), (u'加快', 40), (u'政府', 39), (u'创新', 36), (u'完善', 35), (u'全面', 35), (u'企业', 35), (u'促进', 34), (u'提高', 32), (u'就业', 31), (u'实施', 31), (u'中国', 31), (u'工作', 29), (u'支持', 29)]
从中可以看出2017年的前五关键词是:发展,改革,推进,建设,经济,和我们经常在媒体上看到的情况也比较吻合。
思路是这样的,首先从汇总页面获取到每年政府工作报告网页的链接,然后分别爬取每个链接获取到网页内容,接着解析出每年的政府工作报告正文,最后对每10年的政府工作报告合并分析出Top20关键词并展示出来。
导包:
汇总页面URL:
从汇总页面解析出每年政府工作报告全文页面的URL列表:
从报告正文页面html中解析出正文内容:
注:这里要考虑两种不同的页面结构进行解析。
通过上述函数结合使用,可以爬取到1954年到2017年的所有政府工作报告的文本,总字数为100万零7000多字。
接着以下几个函数用来解析关键词:
汇总以上代码,合并为summary_analysis.py文件,内容如下:
运行该文件,在当前目录下的out.tmp文件可以看到其内容如下:
【1954-1964】 我们:932;人民:695;国家:690;我国:664;建设:650;发展:641;社会主义:618;生产:509;工业:491;农业:481;工作:396;增长:385;增加:376;必须:361;计划:339;已经:328;方面:299;进行:298;全国:295;企业:267;
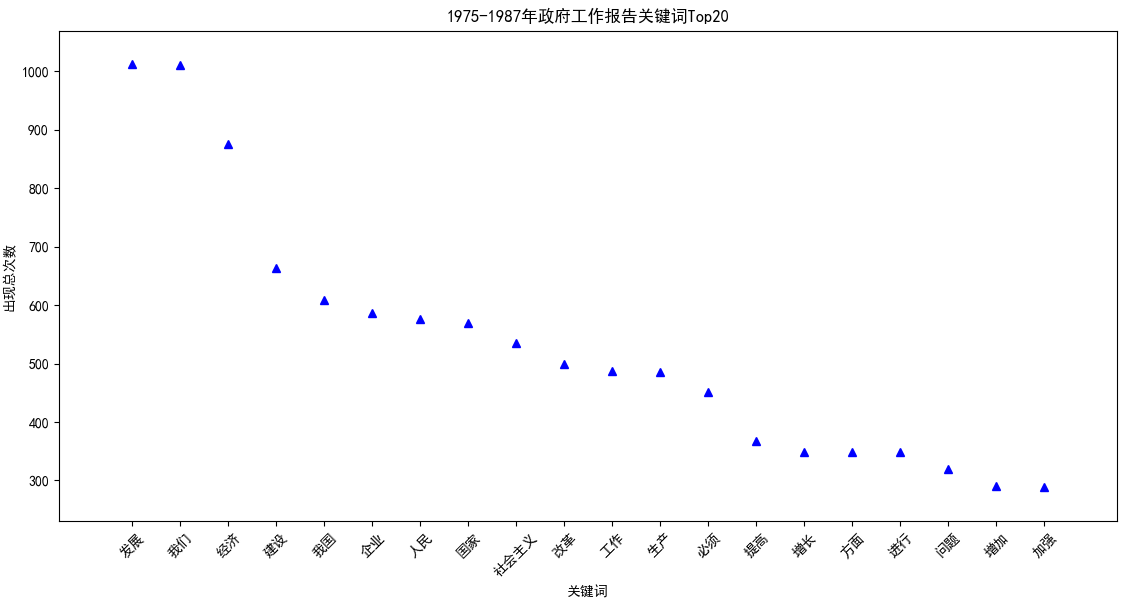
【1975-1987】 发展:1012;我们:1011;经济:875;建设:664;我国:609;企业:586;人民:577;国家:569;社会主义:535;改革:499;工作:488;生产:486;必须:451;提高:368;增长:349;方面:349;进行:349;问题:320;增加:290;加强:288;
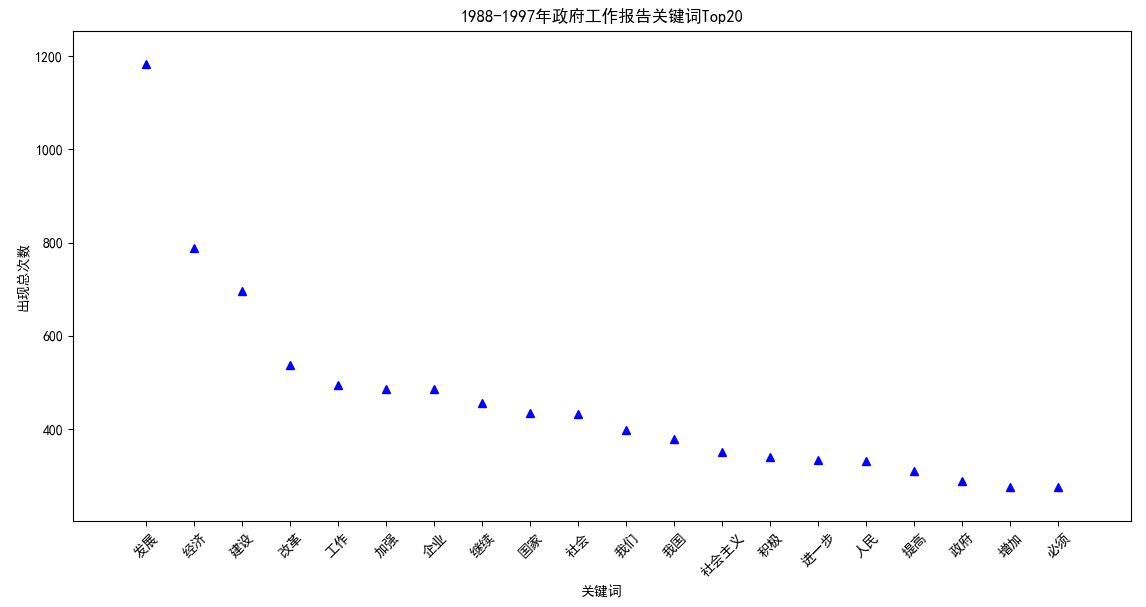
【1988-1997】 发展:1182;经济:789;建设:696;改革:537;工作:495;加强:485;企业:485;继续:455;国家:435;社会:432;我们:399;我国:378;社会主义:350;积极:340;进一步:334;人民:331;提高:311;政府:289;增加:276;必须:275;
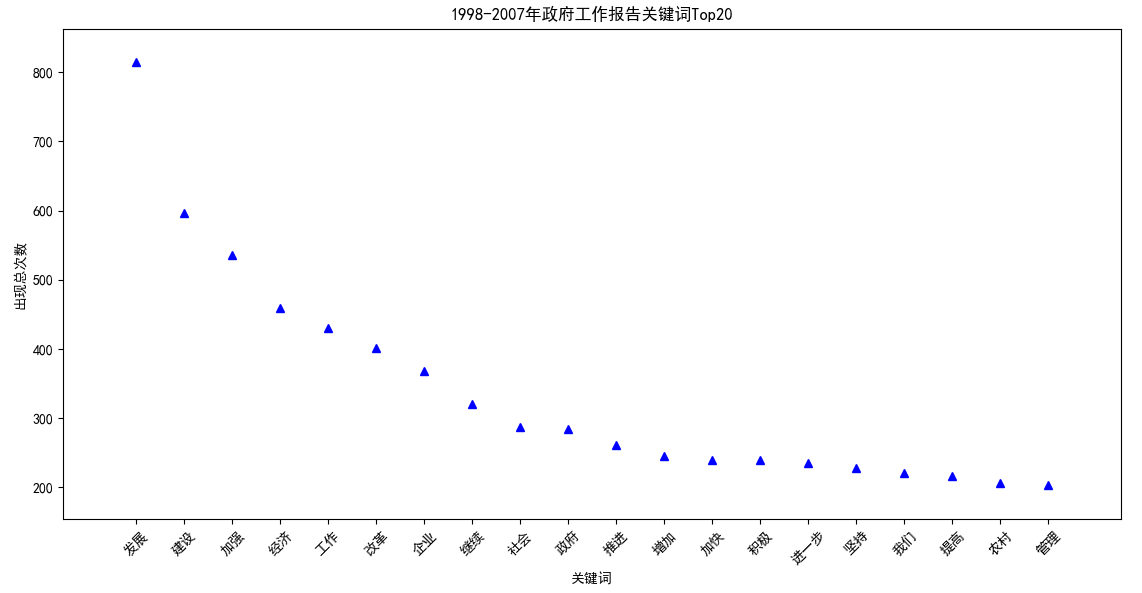
【1998-2007】 发展:814;建设:597;加强:536;经济:459;工作:430;改革:402;企业:368;继续:320;社会:287;政府:284;推进:261;增加:245;加快:240;积极:240;进一步:236;坚持:228;我们:221;提高:217;农村:207;管理:203;
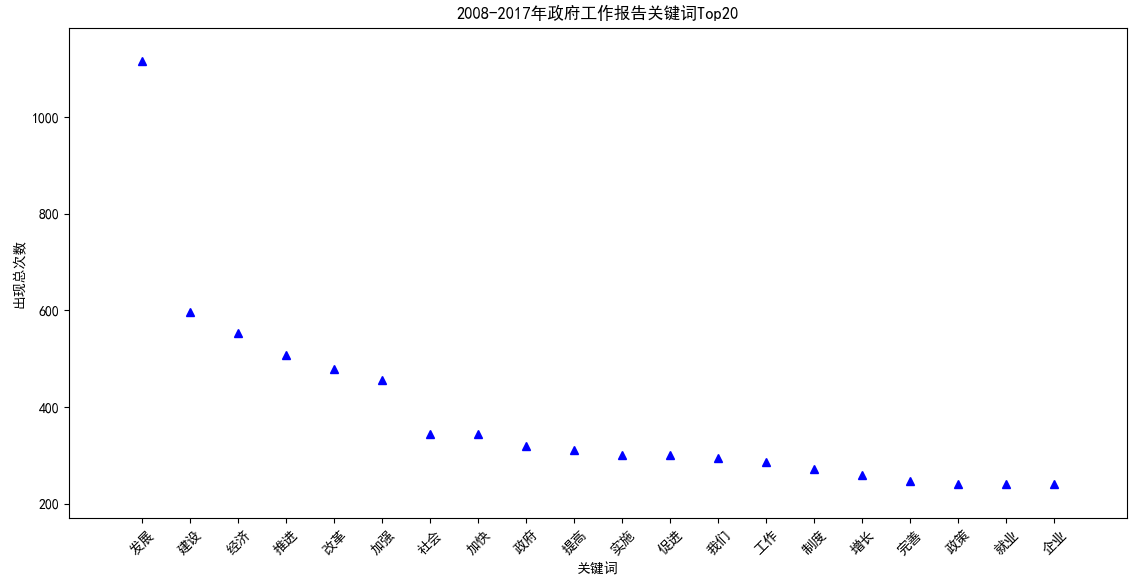
【2008-2017】 发展:1115;建设:597;经济:554;推进:507;改革:479;加强:456;社会:345;加快:344;政府:320;提高:312;实施:301;促进:301;我们:294;工作:287;制度:272;增长:259;完善:248;政策:240;就业:240;企业:240;
同时也绘出了5张图,分别如下:
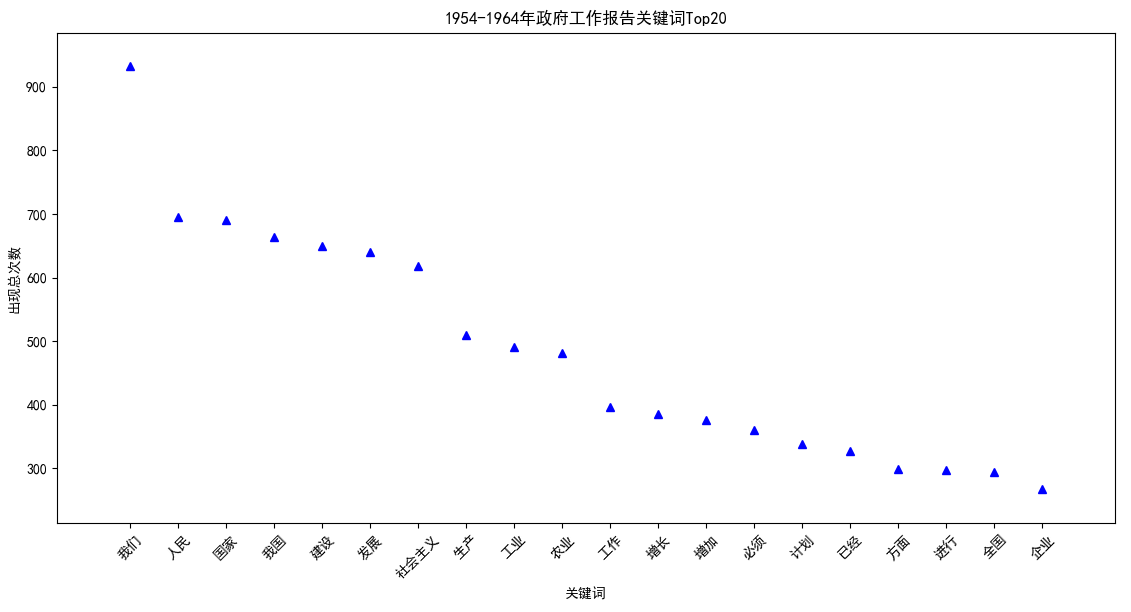
从以上5张图可以看出,1954~1964年间,“我们”是绝对的关键词,其次第二梯队是:人民,国家,我国,建设,发展,社会主义,第三梯队是:生产,工业,农业,从中可以感受到鲜明的时代气息。
到了1978年改革开放及其后的十年间,“发展”成为了绝对的关键词,而第二梯队的关键词是:经济,建设,我国,企业...“生产”也是提到的次数很多的关键词。
1988~1997这十年间,“发展”依然是绝对的关键词,而第二梯队的关键词基本还是:经济,建设,改革,企业....
1998~2007是进入新世纪的十年,“发展”的主旋律依然没有变化,“农村”这一关键词进入前20,体现国家对农业的重视。印象中也就是在这几年间国家取消了延续了2000多年历史的农业税,从此不用再“交公粮”了。
再看最近的十年:2008~2017,“发展”依然是第一要务,而“制度”、“政策”、“就业”等关键词进入前20,具有新时代的特色。
GitHub