搜索引擎要解决的就是数据库分库分表后的模糊查询功能

实际应用中,要求搜索框的值能去搜ID、名称、介绍、标签,还能将结果聚合显示,这依赖的就是搜索引擎
搜索引擎中的数据来自于数据库,若该数据也在redis中保存,则修改了数据库需要同时修改redis和搜索引擎,为了提高响应时间,可以使用线程池或者队列的方式来异步执行这一修改操作,只要实现最终一致性就行。
因为数据库修改后传递给redis速度很快,而搜索引擎需要重新建立索引,相对较慢
Lucene是apache旗下的顶级开源项目,在java搜索引擎方面类似于开山鼻祖
目前还处于一线维护状态,项目维护频率较高,它是一个类库,只需要加入对应的Jar包即可集成搜索功能
在它之下又演化出两个子项目
- solr
- ElasticSearch
这两个子项目都是基于Lucene做的二次开发,都自带一个web容器,且对外提供功能API,都是文档类型数据库,能存数据
没有完美的框架,鱼和熊掌不可兼得
特点
托管于apache,在初次建立索引时较慢,但是在修改时,相对较快
应用
一般用来做业务搜索引擎
特点
开源的商用类型项目,与solr相反,初次建立索引时较快,修改时,相对较慢
应用
一般用来做数据统计引擎
搜索引擎不只能做搜索,也能做数据统计、数据分析、日志分析
Elastic Stack简称ELK,是ELK Stack的更新迭代产品,由Elasticsearch、logstash、kibana、Beats这四个模块组成,Elastic拥有完整的日志分析技术栈,可以更加方便的做日志管理系统,提供一套完整的数据显示页面
- ElasticSearch:是一个搜索和分析引擎,建立搜索索引以及提供相关功能,ELK核心
- Logstash:是服务器端数据处理管道,客户端分布在不同的服务器上,logstash能够同时从多个客户端采集数据,向服务端发送日志,并将搜集的日志格式化后存储在诸如Elasticsearch等“存储库”中
- Kibana:提供一套完整的web中控,可以让用户在Elasticsearch中使用图形和图标对数据进行可视化
-
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
-
Solr可以独立运行,运行在Jetty、Tomcat等Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。
-
Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。
-
Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况
-
Solr默认使用jetty作为服务器
下载solr的压缩包并放到Linux的opt目录下进行解压,得到一个文件夹
创建Solr数据和安装目录
进入 solr-5.5.5/bin/ 目录,可以看到有如下内容
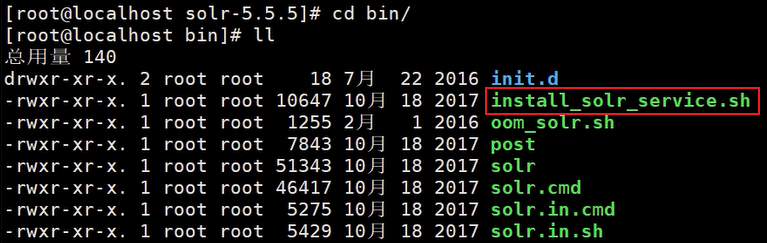
执行下面的代码安装solr,这种安装方式会把solr以服务的形式安装,相比redis或tomcat的安装方式有所不同,后者配置文件需要变化,从而创建不同的实例,而前者是单实例,不需要反复启动
安装完成就会默认启动,此时会提示solr运行在8983端口,所以我们需要手动把这个端口加入防火墙白名单

现在可以尝试在win或mac系统下访问运行着solr的虚拟机了,通过虚拟机的ip+端口号就能访问到solr,实际开发中这种是不对外开放的,能对外开放的只有Nginx服务器

服务器日志,刚启动时是空的
可以在level选项页中调整日志的显示级别
线程列表
在线创建一些目录,实际开发中不会通过这种方式去干,而是通过命令行创建
现在整个solr是刚创建的状态,此时可以看到左侧侧边栏最底部提示“没有可用的核心”
solr作为文档型数据库,并没有库的概念,只有文档集,叫core,core存放着文档、文档字段类型配置、索引等信息
一般通过命令行创建core
命令运行后,就会拷贝出一份core到var目录下

进入这个目录,就可以看到有如下文件

进入conf,可以看到有许多配置文件和文本文件,比如储存屏蔽词汇的“stopwprds.txt”,里面是空白的,需要自行添加或者去网上找

创建core后,在网页管理系统上就能查看core的配置
从上图的“core selector”选中core,就能进入core管理页面,这是一个下拉列表,可以看出core可以配置多个
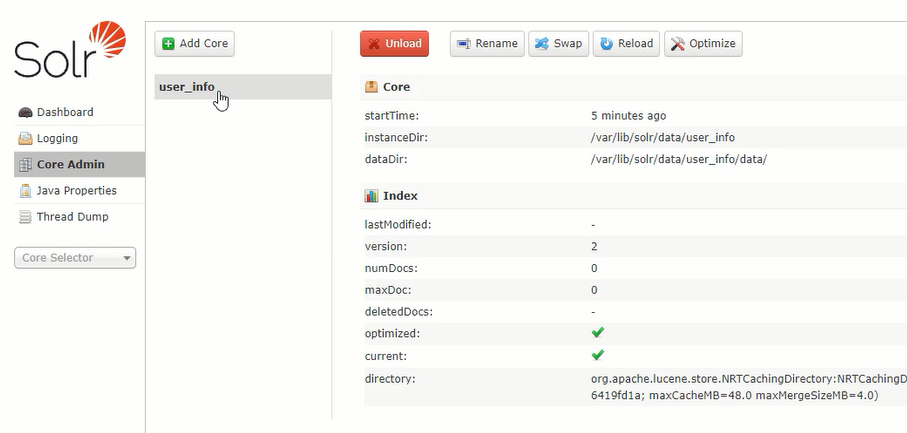
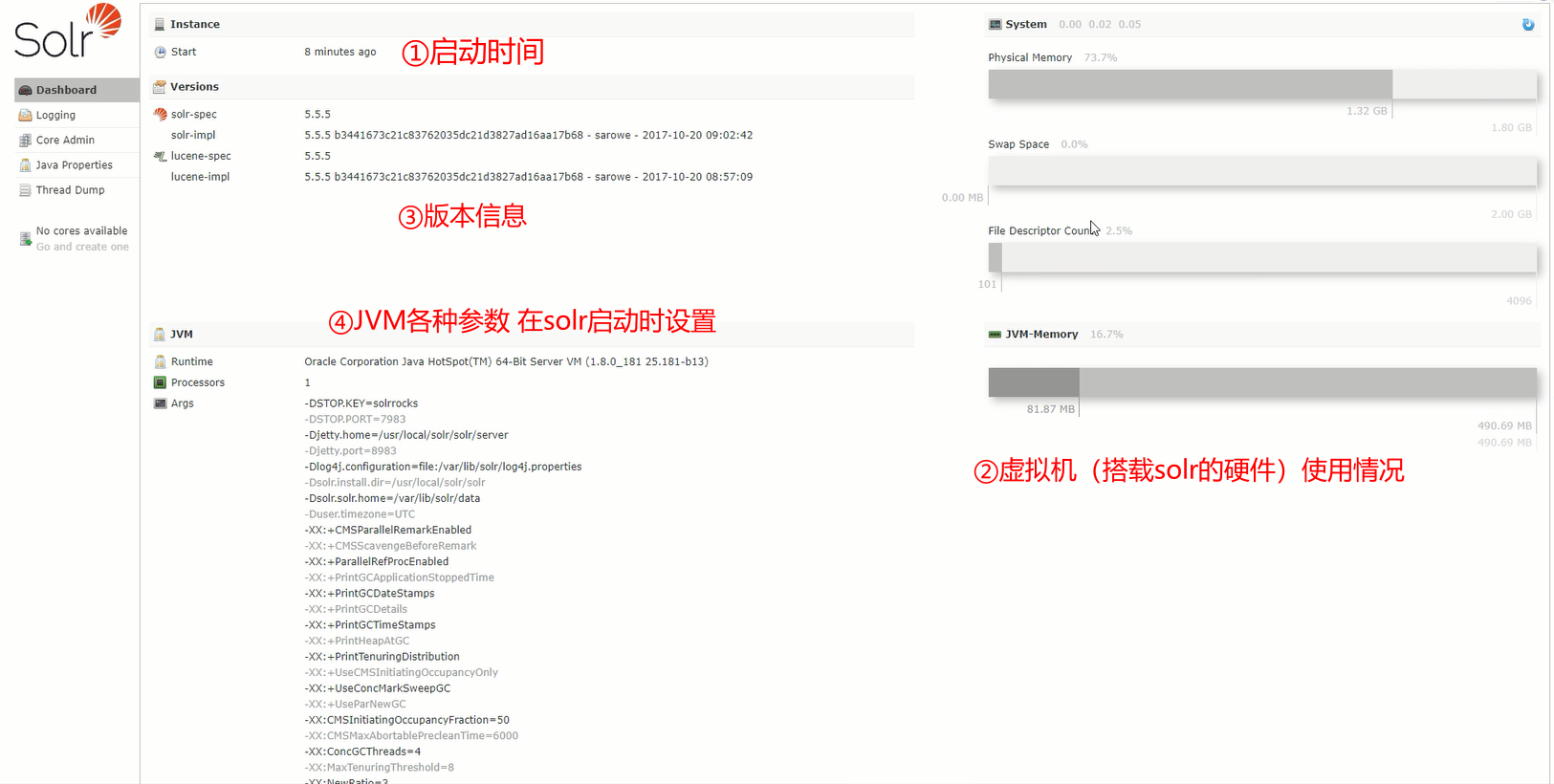
core管理页面的首页,可以查看各类信息
6.3.3.1 介绍
用于进行数据统计和分析的页面,比如对字符串进行分词
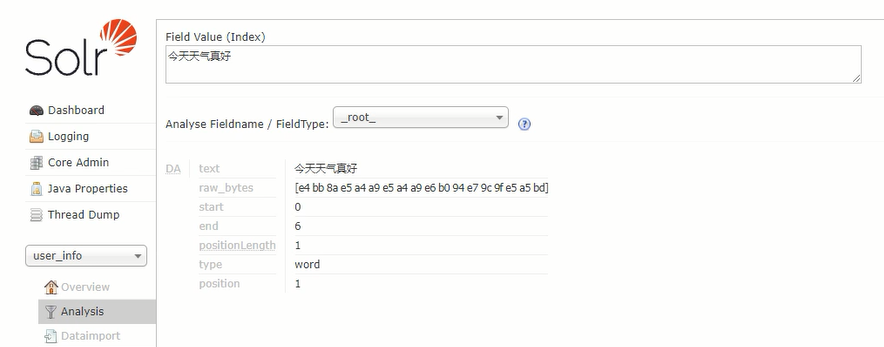
分词:一般中文搜索,都希望搜索时,是词汇搜索,因为词汇搜索时,命中率更高,所以会在搜索引擎中加入分词器
比如:今天天气真冷啊
拆分为:【今天】【天天】【天气】【真冷】【啊】
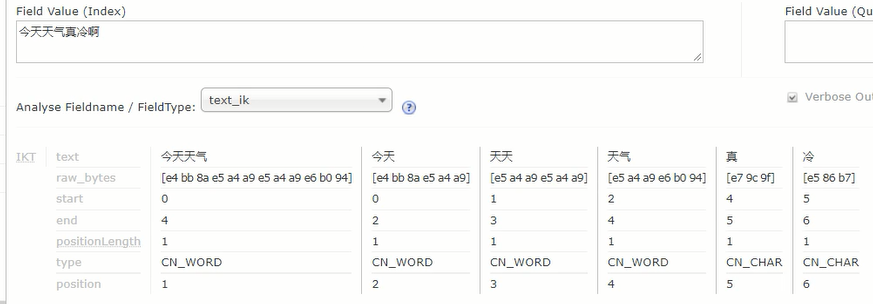
分词器:通过调整“Analyse Fieldname”可以设置不同的分词器,solr自带的分词器毫无功能,所以要自己添加,比如IK分词器,分词器与solr的版本要一致

6.3.3.2 分词器安装步骤
-
将IK-solr的Jar拷贝到/usr/local/solr/solr-5.5.5/server/solr-webapp/webapp/WEB-INF/lib/
-
修改managed-schema配置文件(/data/solr/data/newcore/conf/)
-
添加IK分词配置
- 添加DynamicFiled动态字段
- 重新启动solr
6.3.3.3 IK分词器效果演示
安装好IK分词器后,就能得到如下分词效果,如果感觉还不够好,就得找商业化的收费的分词器,这方面做的最好的就是各种输入法公司,因为他们可以收集用户输入文字时的分词信息,以此为依据制作出分词器,这就是输入法公司免费提供用户时候还这么挣钱的原因
导入数据到core中,注意导入的数据id唯一,如果导入的数据id相同则发生数据覆盖,如果导入的数据不设置id的value,那么core会给数据自动生成一个value
在线预览目前core中的文件
点击就能查看服务器延时情况
在线安装各种插件,并查看各种插件的版本等信息
在线查询面板,点击execute query就能从core中查询并返回指定格式的数据,可以查询到documents面板中添加的数据
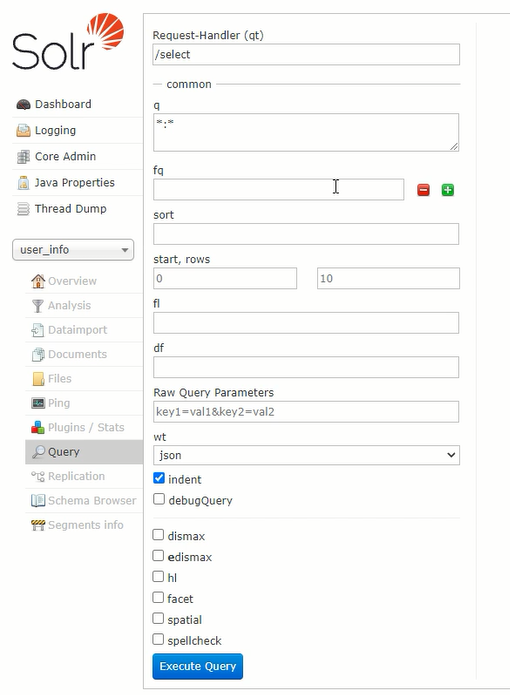
通过files可以查看当前core中的文件,其中managed-schema记录了core的字段以及字段的设置
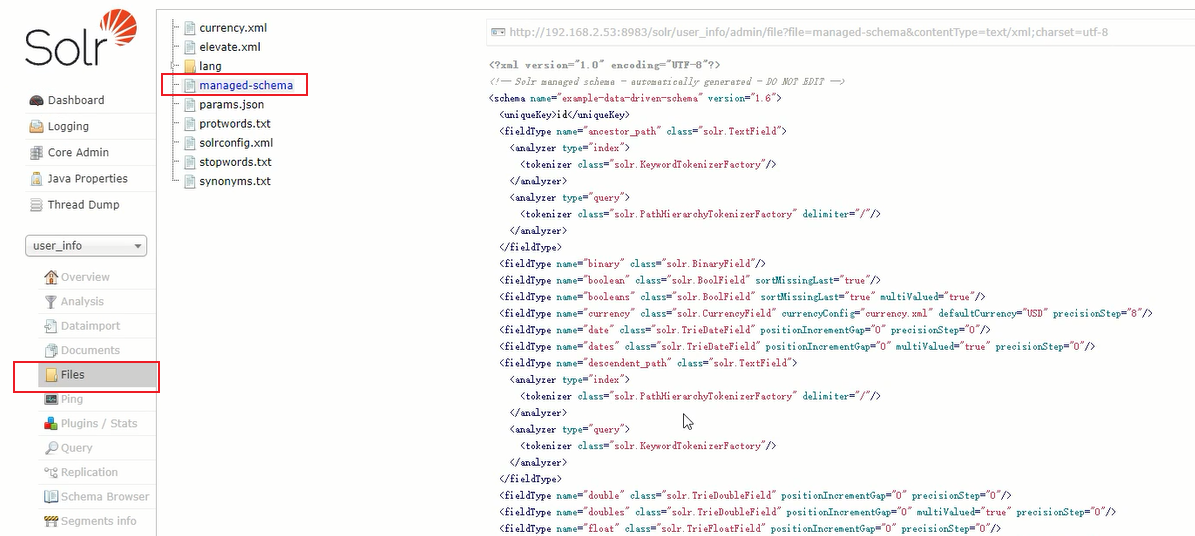
这些字段和字段的设置依据就是创建core时指定的data_driven_schema_configs (节点的配置文件)

id字段有唯一约束

通过fieldType标签设置了所有字段类型,定义了当前Solr默认的一些数据类型[可扩展]
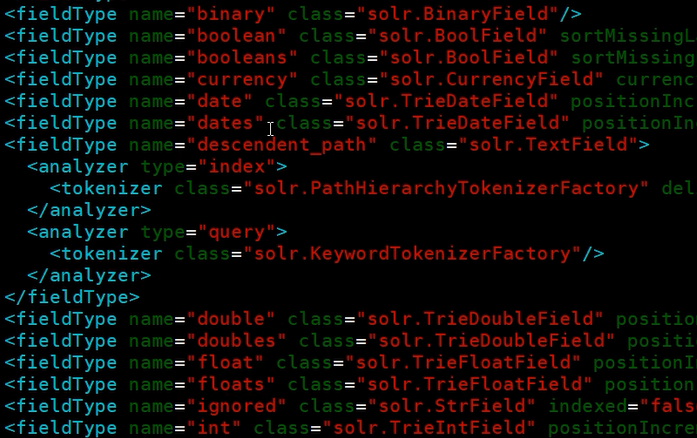
有的数据类型名字加了“s”,并多了一个multiValued的属性,这表示的是数组

每一个fieldType标签都有一个analyzer标签,用于设置该数据类型的分词配置
默认的配置一般没法用,需要自定义分词配置

字段声明.,定义当前core所使用的字段,若不声明直接给core添加数据,则会默认添加一个field标签,类型为Strings
其中只有name和type两个属性的field标签属于人为加入的字段,还带其他各种属性的属于core最初自带的字段

stored说明:
建立起索引,并不一定要保存,只有搜索时希望返回结果时才需要设置这个值为true,比如搜索张三,希望搜索到张三时能把对应的结果返回,此时设置为true,比如搜索小说的章节,只希望把第几章返回,而不需要返回这一章节那大几千的正文,此时这个值就为false
动态字段,不想添加field时,可以选择使用字段加上动态字段的后缀实现对存入数据的数据类型的声明
例如,存入数据时key后加“_s”,这就会触发DynamicField标签

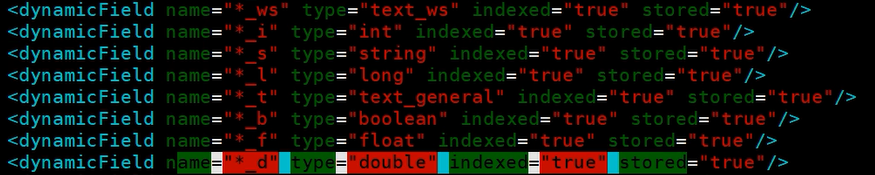
此时查看数据,可以看到存入的数据类型已经不是数组了,而是单个值

并且自定义的那些“age_i”“score_d”不会生成field标签,也就是不会被保存下来,如图,还是原来的数据

在springboot中已经集成了,只需要找到带solr的启动器,复制到pom.xml中


yml加入solr连接参数
整个springboot项目最后是要打包放到服务器的linux下运行,所以这里配置的是虚拟机ip,正是以后运行springboot项目的地方

任何加入了springboot的starter的东西,都有一个对应的AutoConfiguration,能指明如何使用这个东西,所以要学会如何使用solr,可以查看solrAutoConfiguration
通过查看solrAutoConfiguration,可以发现有一个叫SolrClient的抽象类
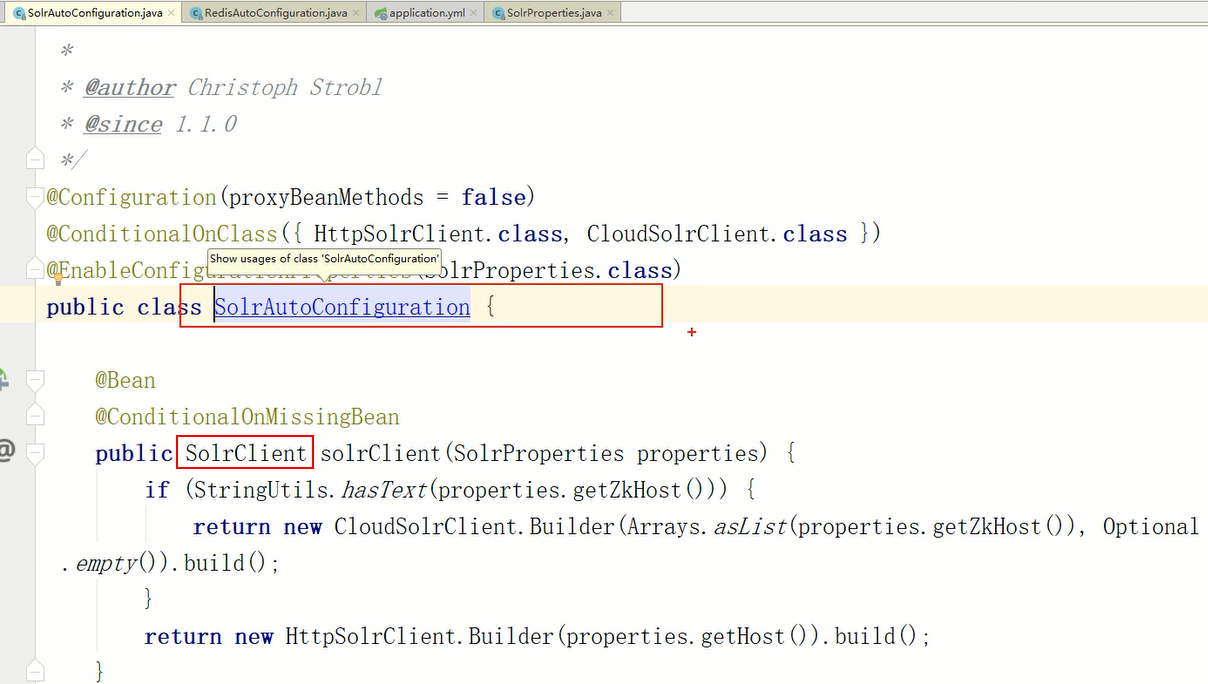
现在的目标是给solr的core存值,查看这个抽象类的实现类提供的方法,可以发现存在许多名叫add的方法
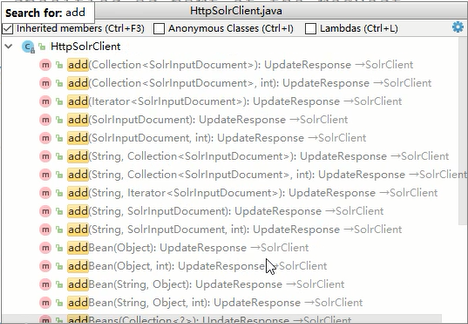
随便找一个查看实现类提供的方法的注释,可以知道这个方法就是把一个SolrInputdocument类存入指定的core中,参数collection就是要传入的core名
但有的add方法又不需要

在浏览器访问solr管理页面的core,可以看到浏览器路径名带上了core,所以如果在yml配置中直接指定了core名,那么就不需要再传入参数collection了
下图是当前yml配置,并没有写死core名,所以这种不带collection参数的add方法不要用
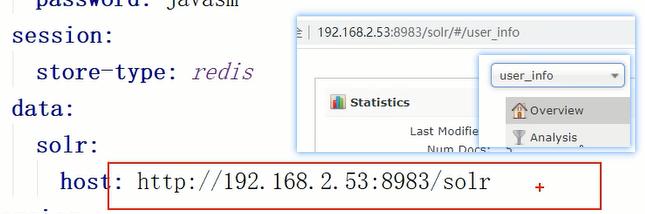
已经知道了要向solr的core存入数据时,需要调用的add方法以及方法需要的参数,现在就要准备一个SolrInputdocument对象
首先创建一个SolrInputdocument类,首先查看它的构造函数参数列表,看它需要传入什么东西,可以看到它可存入可变参数列表或者map

进入这个类,进一步查看它的构造函数,可以发现它要求存入的可变参数的长度必须是偶数,这样才能组成k-v组
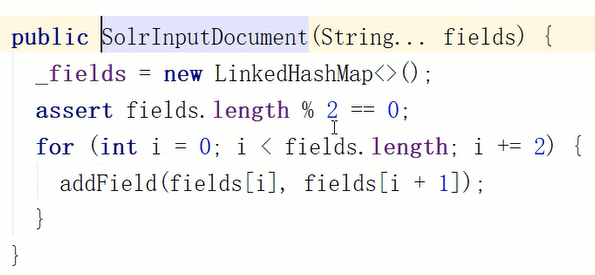
然后通过调用addField方法存入一个linkedHashMap

再查看这个类提供的方法,看到它提供add方法,所以可以通过调用这个类的实例的这些方法,直接把对象、集合、字符串+obj存入这个对象
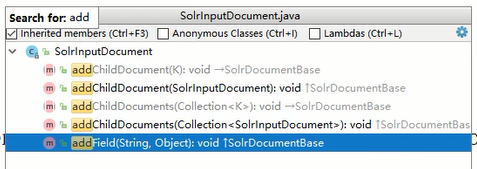
所以现在知道了,在springboot项目下,要想向solr的core存入数据,需要先创建一个SolrInputdocument对象,而这个对象的目的是将传入的数据组成k-v保存为map,或者直接保存传入的map
现在手动设置一些数据存入
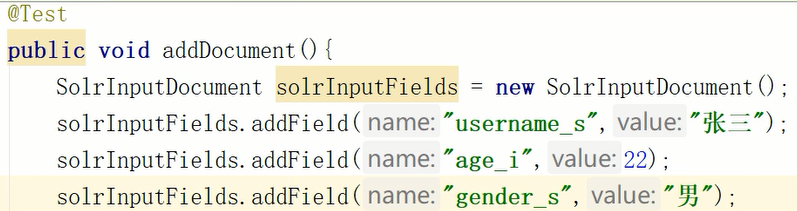
现在有了带数据的SolrInputdocument对象,直接调用solrClient对象的add

控制台没有报错,说明过程没问题

但是查看core中的数据,没能找到存入的数据
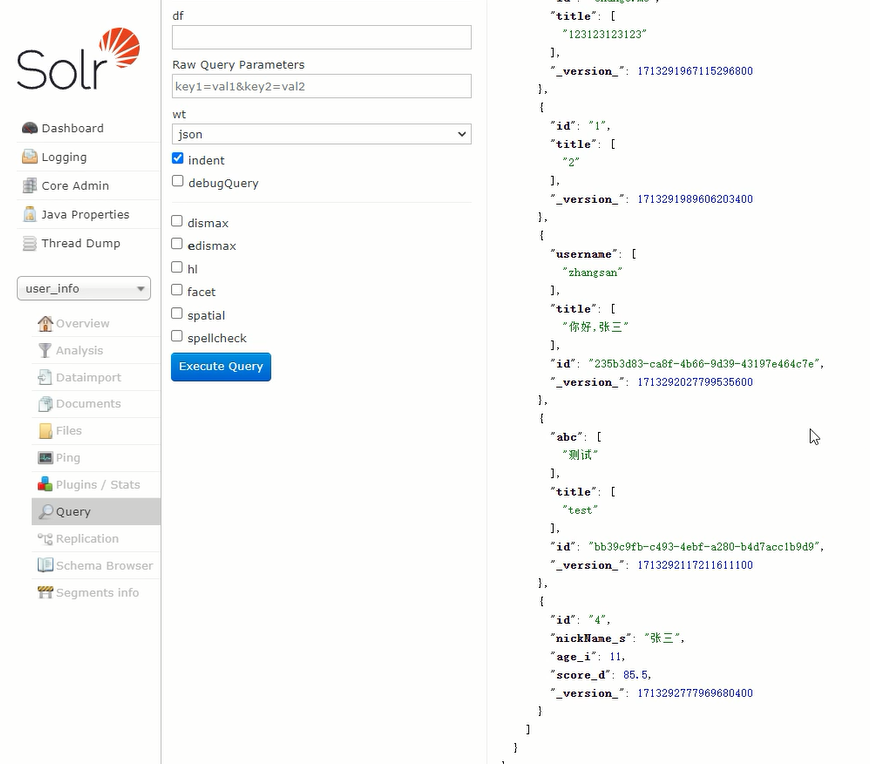
此时分析可能是缺少类似flash或者close或者commit的方法
考虑到solrClient是一个单例,如果close后其他方法就没办法使用了,所以可以确定是缺少了flash或者commit

尝试着查看solrClient对象的方法,果然发现了commit方法
调用这个方法,前端查看core数据,找到了后端存入的数据

首先在pom.xml中添加启动器

然后给测试类加上@springbootTest,这就会以spring容器的方式启动测试类,并加载yml配置文件

最后在要测试的方法上使用@Test即可

要给solr的core存值,就要使用solrClient.add方法,这个方法需要传入
上面的探究过程在这个测试类中完成的,测试类代码如下:
solr传入bean时报错 class: xxx does not define any fields
上面的代码中,向core中存入字段非常费劲,实际开发中,基于mybatis,从数据库中查出来的数据都是对象,而且还要根据业务需求转为VO类,因此要探究如何将VO对象中的数据转为字段存入core
已经有了上面的分析过程,那么这里直接指明,可以找到addBean这样的方法,根据这个方法的注释说明,首先给VO类中private类属性添加@Field注释,然后就可以调用这个方法了
下面是代码
只需要调用solrClient的delete方法,记得使用commit提交,事实上,只有查询不需要commit
删除方式有两种,一种是删除指定id的数据,一种删除查询出来的结果,但是一般都是前者,精确删除,哪有人用后者这种方式
要执行查询方法,首先要找到查询方法,从solrClient提供的方法中找一找,可以看到有一个方法叫query,需要的参数为solrParams

查询的单词通常为select或者query,全局搜索 solr+select没找到方法,搜索solr+query找到了solrQuery类
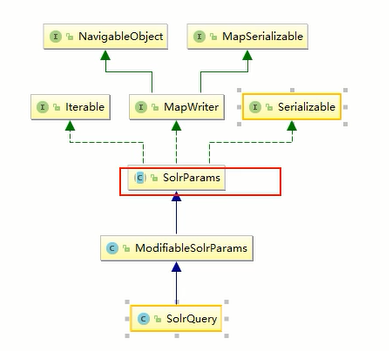
根据这个类的注释,可以知道这个类提供getsetadd方法以获得solrParams

根据这个类的关系,可以看到这个类是solrParams的父类,那么父类自然可以被传入solrClient的query方法中
此时可以先创建这个对象,然后查看这个对象的构造函数

可以发现它需要一个参数q,这和solr管理页面中query页面的设置一样,这其实就是一个描述符,用于指定字段和值,输入*代表匹配所有,即查询所有
接着调用solrClient的query方法,这个方法的返回值是一个queryResponse对象,查看这个类的注释,可以知道这个对象提供了从中获取查询结果的方法
使用getResults方法,获取结果集,结果集如图,可以看出这是一个list集合

然后分别从结果集中取出总记录数(numFound)、开始索引(start),并通过forEach循环从中取出元素,使用getFieldValue获取指定字段的值

上面的代码中,查询到的数据返回时使用了foreach循环,实际开发中回传一个对象给前端
要实现这种效果,只能从QueryResponse 和SolrdocumentList 考虑,前者没有相关方法,后者尝试着搜索,就搜索到了,通过getBeans方法,实现了回传list集合


通过调用SolrQuery对象提供的方法,可以设置一些查询条件,能设置的条件可以参考solr的管理页面提供的输入框
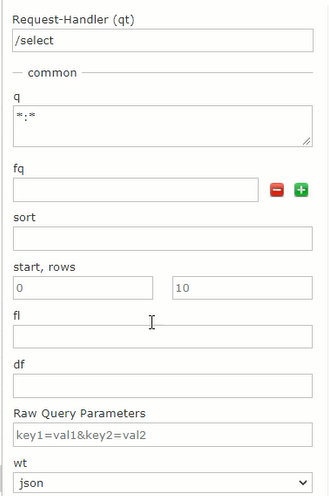
查询条件及结果:

SolrQuery对象提供setSort和addSort两种排序方式,前者用于修改排序方式,后者用于添加排序方式

如图,设置按照id字段排序,排序方式为desc(降序)
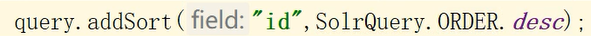
结果

之前创建SolrQuery对象时,参数p用代表查询所有,现在将替换为具体的字符串,多个字符串用空格间隔,这就实现了全文匹配 不区分字段

结果

设置如图
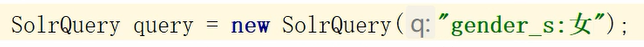
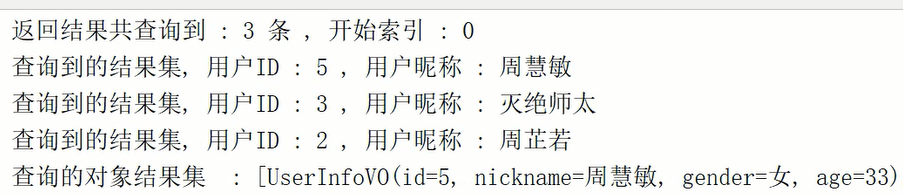
结果:
之前的两种方式都算单查询条件,如果希望设置多个查询条件,可以调用SolrQuery对象的set方法
这个方法要求传入条件类型和可变参数

其中条件类型就是solr管理页面中可以看到的那些
例如:

结果:

下面给出上面这些方法的整体代码
统计功能在solr的管理页面上显示为fq,可以传入一个或多个字段,得到查询情况以及统计结果,这个统计结果就相当于mysql的group by
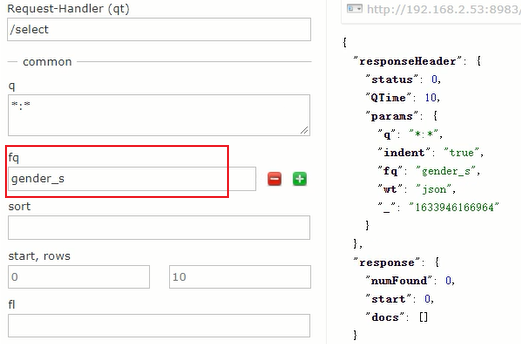
在springboot项目中,首先要开启统计查询,然后添加统计字段,最后遍历返回结果

结果如图

通过对获取到的结果进一步循环取值,得到更详细的数据
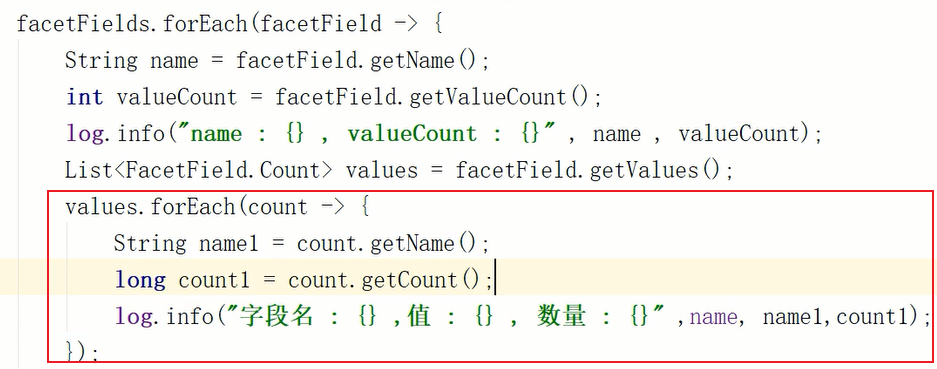

这个功能常见于需要做分类聚合搜索的场景,比如商品存入搜索库中,此时要显示某类商品数量,就可以通过这个功能得到数据
例如商城中,某个参数后会有一个括号,里面实时显示有多少条数据,这种效果就叫分类统计,不可能通过查询mysql实现,那对数据库压力多大呀

在springboot项目中的代码如下